
“The world’s most valuable resource is no longer oil, but data”. (Quelle: The Economist, economist.com) Dieses Zitat und die folgende Darstellung aus dem Fachmagazin “The Economist” von 2017 ist vielen bekannt.

Quelle: The Economist (economist.com)
Doch was genau sind Rohdaten? Wo treten sie auf? Wo werden sie verarbeitet? Und am wichtigsten ist vermutlich die Frage, wie lassen sich aus Rohdaten wichtige Erkenntnisse gewinnen und Ergebnisse ableiten? All diese Fragen werden in diesem Beitrag beantwortet.
Definition Rohdaten
Kurz gesagt sind Rohdaten Informationen, die nicht aus irgendetwas anderem abgeleitet werden können. (Quelle: Butscher R.) Dabei handelt es sich schlichtweg um Daten, die weder vorab geprüft noch bearbeitet werden.
Aus diesem Grund ist es durchaus möglich, dass diese Art von Daten fehlerbehaftet sind. Zudem liegen sie in den meisten Fällen unkomprimiert vor.
Rohdaten entstehen und existieren in allen möglichen Fachgebieten und -bereichen, wobei sie des Öfteren mit den Begriffen Primärdaten oder auch Urdaten gleichgesetzt werden.
Im heutigen Zeitalter von BigData ist der Begriff Rohdaten nicht mehr wegzudenken, wie sich im weiteren Verlauf des Artikels zeigen wird.
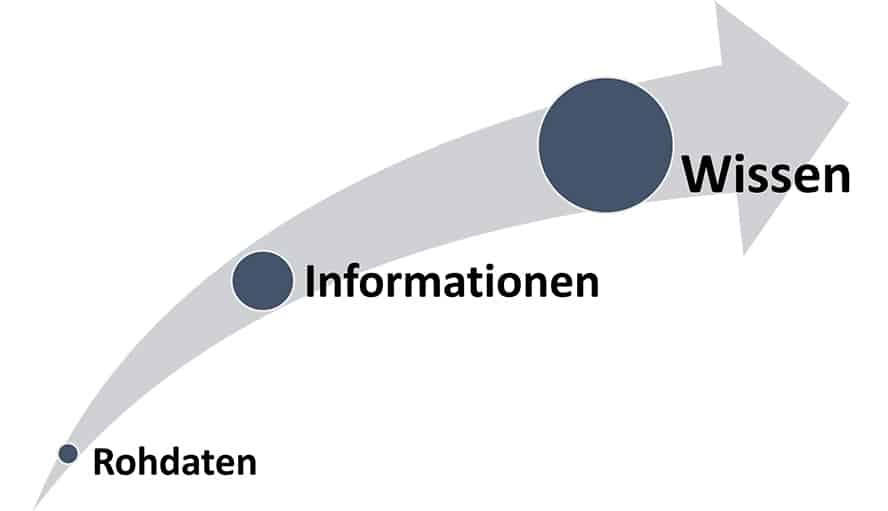
Quelle: eigene Darstellung in Anlehnung an Butscher R.
Wie der Abbildung zu entnehmen ist, sind Rohdaten die erste Quelle, aus welchen wiederum Informationen gewonnen werden können. Anschließend kann aus den Informationen durch Interpretation wertvolles Wissen gewonnen werden.
Wo sind Rohdaten auffindbar?
Die nachfolgenden Punkte verdeutlichen, in welchen Fachrichtungen Rohdaten auftreten. Das Hauptaugenmerk in diesem Artikel soll vor allem auf der Wissensgewinnung im Kontext des Internets, E-Commerce und BigData liegen.
1.1 Film & Fotografie
In der Film- und Fotografie-Branche bezeichnet der Begriff Rohdaten Bild- und Videodateien, welche von einer Kamera erfasst werden und ohne jegliche interne Verarbeitung oder Komprimierung vorliegen.
Diese werden oft auch als RAW-Dateien bezeichnet und enthalten somit alle vom Sensor erzeugten Informationen. JPEG-Dateien sind in der Fotografie beispielsweise komprimierte Versionen der Rohdaten und aufgrund ihrer deutlich geringeren Größe sehr beliebt. (Quelle: adobe.com)
In der Videografie sind RAW-Aufnahmen noch deutlich seltener zu finden, da die meisten Kameras das Videomaterial bereits intern komprimieren. Auch hier liegt der Hintergrund an den immensen Datenmengen, welche dadurch zustande kommen.
Dennoch gibt es sehr hochwertige Kameras, wie beispielsweiße die Blackmagic URSA Mini Pro 4.6K G2, welche eine solches Aufnahmeformat anbieten.
Professionelle Fotografen sowie Produkt- und Imagefilm Dienstleister bevorzugen häufig die Aufnahme der größeren RAW-Formate, da sie deutlich mehr Bildinformationen und somit Möglichkeiten für die Bild- und Filmnachbearbeitung liefern und sich somit hochwertigere Ergebnisse erzielen lassen. Weitere Informationen zum Thema Aufnahme- & Videoformaten findest Du hier.
1.2 Musik
In der Musik- und Tontechnik bezieht sich der Begriff Rohdaten ebenso wie in der Fotografie auf unverarbeitete Daten.
Die Aufnahme kommt somit direkt von der Audioquelle und liegt somit unverändert und unkomprimiert, meist im WAV-Format, vor. (Quelle: lehrerfortbildung-bw.de)
Ähnlich wie in der Fotografie ermöglichen diese Arten von Rohdaten eine höhere Flexibilität bei der nachträglichen Bearbeitung des Audiomaterials.
1.3 Wissenschaft
Auch in der Wissenschaft ist der Begriff Rohdaten gebräuchlich. Diese Art von Daten wird oft im Rahmen von wissenschaftlichen Experimenten, Umfragen oder durch technische Tests generiert. Die Daten können dabei stark variieren.
Die nachfolgende Liste soll beispielhaft physikalische und chemische Rohdaten aus der Wissenschaft aufzeigen:
- Temperatur
- Druck
- Geschwindigkeit
- Elektrische Signale
- Chemische Konzentrationen
1.4 Weitere Fachgebiete
Im Grunde lässt sich feststellen, dass in jedem Bereich, in welchen Daten generiert werden, auch Rohdaten existieren. Um den Rahmen des Artikels nicht zu überschreiten, wurde zur Verdeutlichung nur ein Bruchteil der Themengebiete beschrieben.
Auch die folgenden Bereiche arbeiten mit Rohdaten und sollen nicht vernachlässigt werden:
- Industrie (Messdaten, Sensordaten)
- GPS-Daten
- Medizin (z. B. MRT)
- Klimaforschung
- Bergbau
- Astronomie
Unabhängig von der Fachrichtung ist es vor allem wichtig, dass Rohdaten in ihrer ursprünglichen und unverarbeiteten Form vorliegen. Dies ist zugleich die wohl wichtigste Eigenschaft dieser Daten.
1.5 Komprimierung von Rohdaten
Wie bereits an den Beispielen der Fotografie und Audiotechnik gezeigt, könnte man selbst nach dem Komprimieren von Daten nicht mehr von Rohdaten sprechen, auch wenn dies oft innerhalb der Aufnahmehardware selbst abläuft.
In der Datenkomprimierung ist hier von verlustbehafteter Kompression die Rede, da der Urzustand nicht mehr hergestellt werden kann. Folglich kann eine RAW- oder WAV-Datei zu einer JPG- oder MP3-Datei komprimiert werden, jedoch nicht andersherum.
Die nachstehende Abbildung soll das Phänomen verdeutlichen:
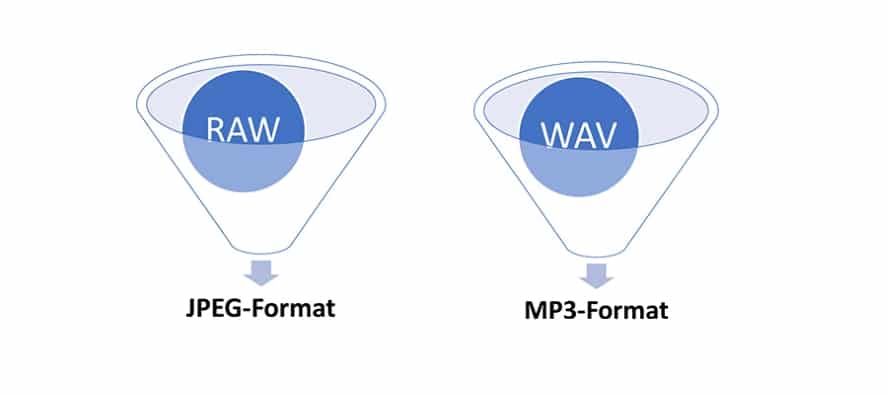
Es sei erwähnt, dass durchaus Algorithmen existieren, welche eine verlustfreie Kompression garantieren. Vor allem Textdateien können sehr gut verlustfrei komprimiert werden. Dies ist beispielsweise durch verschiedene Kodierungsmethoden, wie zum Beispiel durch ein Wörterbuch möglich:
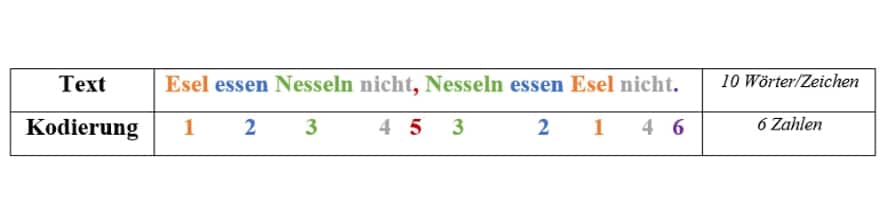
Wie in der Darstellung zu sehen, wurde jedem Wort des Satzes eine Zahl zugewiesen. Aus zehn Wörtern und Satzzeichen wurden somit sechs Zahlen, wodurch Speicherplatz eingespart werden kann. Mithilfe eines Wörterbuches und der vorgegebenen Kodierung, kann somit rückwirkend auf den Satz geschlossen werden.
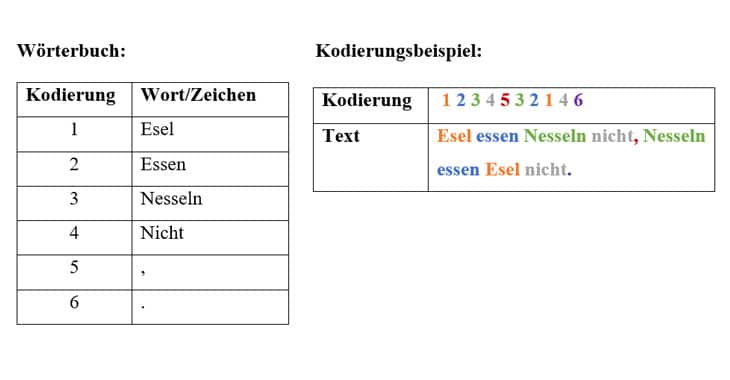
Das Beispiel soll lediglich verdeutlichen, wie mithilfe einfacher Methoden eine verlustfreie Kodierung möglich ist.
(Quelle: Wilke C. (2020), Datenvisulisierung – Grundlage und Praxis, oreilly.de)
Beispiel von Rohdaten
Am einfachsten lassen sich Rohdaten an realen Beispielen darstellen. Wie bereits gezeigt, gibt es diverse Bereiche, in denen Rohdaten auftreten können. Je nach Bereich und Datenquelle variiert natürlich der Prozess der Auswertung und das Ergebnis.
Der Fokus wird aber in diesem Artikel auf Rohdaten im Zusammenhang mit dem Internet gelegt, da der Begriff in der heutigen Zeit zunehmend mit der Digitalisierung in Zusammenhang gebracht wird.
3.1 Shop Bewertungen
Ein einfaches Beispiel für Rohdaten bieten E-Commerce Kundenbewertungen in einem Onlineshop. In diesem Fall wird das Schmuck- und Uhrenunternehmen THOMAS SABO als Beispiel herangezogen.
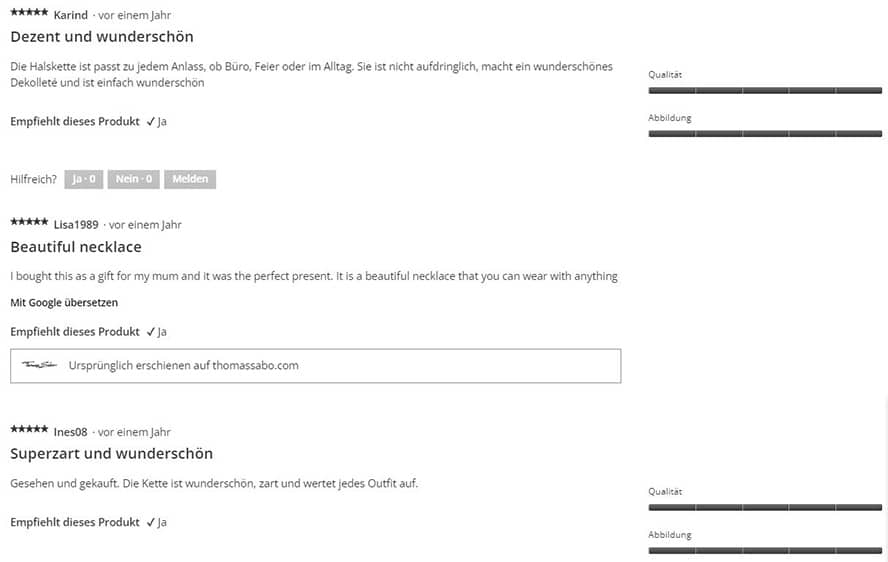
Quelle: thomassabo.com
Die Bewertungen auf der Produktdetailseite, welche der Kunde oder die Kundin abgeben kann, bestehen aus mehreren Einzelheiten:
- Sternebewertung (1 bis 5 Sterne)
- Titel der Bewertung
- Detaillierte Beschreibung
- Qualität des Produkts
- Vergleich des Produkts mit der Abbildung
Diese Art von Daten stellt in diesem Fall die Rohdaten dar, da sie in ihrer ursprünglichen und unbearbeiteten Form vorliegen.
Werden die einzelnen Bewertungen (Rohdaten) nun für das Produkt aggregiert, wie im folgenden Bildausschnitt zu sehen, so ist dies nicht mehr der Fall:
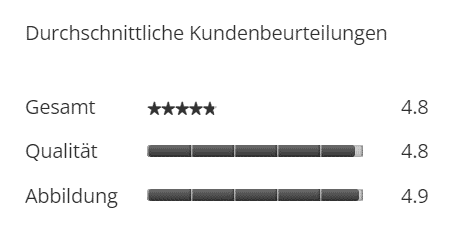
Quelle: thomassabo.com
Hier sind lediglich die durchschnittlichen Gesamtwerte zu erkennen. Aus diesen Informationen kann nicht mehr auf die ursprünglichen Daten zurückgeschlossen werden, weshalb es sich hier nicht um eine Form der Rohdaten handelt.
Diese Datenform bietet zwar einen guten Überblick und benötigt weniger Speicherplatz, lässt aber auch deutlich weniger Analysemöglichkeiten zu.
3.2 Aktienkurs
Ein weiteres alltägliches Beispiel findet sich am Aktienmarkt. Die folgende Abbildung zeigt den Kursverlauf der Alphabet (EX Google) Aktie am 28. Juli 2023.
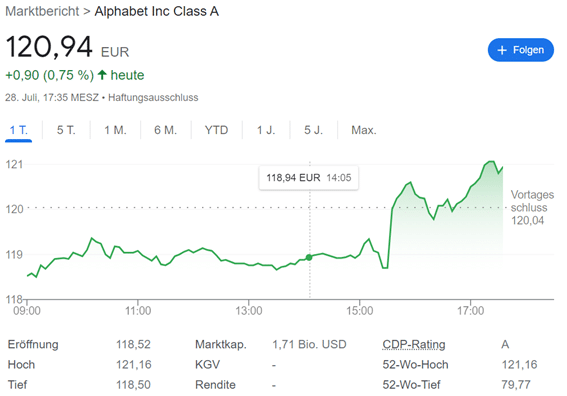
Quelle: Google
Durch die „minutengenaue“ Dokumentation (5-Minuten-Takt im Graf) der Kursdaten lässt sich sehr gut der Kursverlauf über den Tag hinweg erkennen. Erst durch diese detaillierte Darstellung lassen sich tiefergehende Fragen beantworten.
Werden die Daten nun wieder zusammengeschlossen und ein Tageshöchst- und Tagestiefstwert gebildet, wie unter der Grafik zu sehen, so kann nicht mehr von Rohdaten gesprochen werden. Eine Auswertung über den Tag hinweg ist somit rückwirkend nicht möglich.
Die vorangestellten Beispiele und Bereiche sollten ein gutes Grundverständnis für die Begrifflichkeit liefern. Zudem wurden bereits einige positive wie auch negative Eigenschaften der Rohdaten gesammelt, auf welche nun näher eingegangen wird.
Vorteil von Rohdaten
Der Vorteil von Rohdaten liegt darin, dass durch die beiden Eigenschaften der Ursprünglichkeit und Unveränderlichkeit, die Daten sich bestens für detaillierte und aussagekräftige Analysen und Auswertungen eignen.
Durch sie können viel mehr Informationen gewonnen werden als durch aggregierte Daten. Mehr Informationen bedeuten gleichzeitig mehr Wissen und schließlich detailliertere Auswertungen, wie durch die anfängliche Grafik aufgezeigt. (Quelle: Marz N. (2016), Big Data)
Nachteil von Rohdaten
Die positiven Eigenschaften bringen aber gleichzeitig auch Hürden mit sich. Um wertvolle Erkenntnisse zu gewinnen, müssen Rohdaten zuvor oft bereinigt, formatiert und verarbeitet werden.
Es ist wichtig, die Daten vorab in ein geeignetes Format zu überführen, sodass sie für weitere Anwendungen oder Untersuchungen geeignet sind. Dieser Prozess kann je nach Rohdatenformat und -menge sehr aufwendig und ressourcenintensiv sein.
Zudem benötigt die Speicherung von Rohdaten eine deutlich größere Kapazität als komprimierte Daten.
Um Daten effizient auswerten zu können, werden sie deshalb oft in eine strukturierte Form gebracht. Gerade im BigData-Umfeld fallen deshalb öfters die Wörter strukturierte, semi-strukturierte und unstrukturierte Daten.
Was es mit diesen Begriffen auf sich hat und wie Daten für die eigene Analyse verwendet werden können, soll im weiteren Verlauf gezeigt werden.
Strukturierte und unstrukturierte Daten
Strukturierte Daten sind Daten, welche in einem festgelegten Format vorliegen und eine eindeutige und geordnete Struktur besitzen. Sie sind in definierte Felder aufgeteilt und enthalten Informationen in einer klaren und vorhersehbaren Weise.
Des Weiteren sind sie sind leicht verständlich und können einfach in einer SQL-basierten Datenbank oder einer Tabellenkalkulation organisiert werden.
-> z.B. die Sternebewertung oder der Name einer E-Commerce-Bewertung. (strukturiert)
Im Gegensatz dazu existieren unstrukturierten Daten, welche keine festgelegte Form besitzen und meist schwer zu interpretieren sind. Damit sie verarbeitet und für Analysen genutzt werden können, müssen sie deshalb zuerst in eine Struktur überführt werden
-> z.B. der Beschreibungstext der E-Commerce Bewertung. (unstrukturiert)
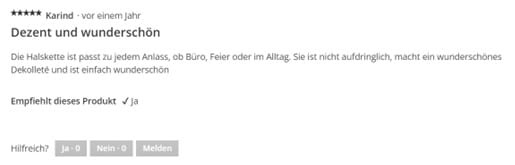
Hier siehst Du das Beispiel auf der Website (Quelle: thomassabo.com)
Sternebewertungen sind trivial zu interpretieren. Im Onlineshop von THOMAS SABO existieren Bewertungen mit eins bis fünf Sterne, wie es in den meisten E-Commerce-Shops üblich ist.
Eins ist dabei die schlechteste und fünf die bestmögliche Bewertung. Beschreibungen in Form eines Textes sind hingegen nicht so einfach zu analysieren. Sprache, Sprachstil, Wortwahl und Satzbau eines Verfassers bzw. einer Verfasserin sind auf der ganzen Welt unterschiedlich, weshalb die Texte zuerst in eine geeignete Form für weitere Analysen gebracht werden müssen. (Quelle: Reuter W. (2023), strukturierte und unstrukturierte Daten)
Ein weiteres Beispiel zeigt der folgende Verkaufstext, welcher so aus einem Zeitungsartikel entnommen werden kann. Anhand dieses Textes wird nochmals der Unterschied zwischen strukturierten und unstrukturierten Daten aufgezeigt. Der Text stellt den Ursprung und somit die Rohdaten dar:
Fiktive Zeitungsanzeige:
Ich verkaufe vier Smartphones. Ein rotes gebrauchtes iPhone 13 mit 128GB zum Preis von 140 EUR. Weiterhin verkaufe ich ein Samsung Galaxy S21 (512GB) in Blau für 310 EUR – das Smartphone ist unbenutzt und neu.
Für 510 € biete ich ein grünes Apple iPhone 13 mit 256GB Speicher an. Das Handy hat einige Gebrauchsspuren am Display und biete ich deshalb für schlappe 420 Euro an. Außerdem biete ich noch ein kaputtes Huawei Pro 30 Lite mit 256GB und in Schwarz für 50 € an.
Dieser Text, welcher wie beschrieben die Primärdaten darstellt, ist unstrukturiert und somit schwer zu analysieren und zu interpretieren. Aus diesem Grund wird der Text nachfolgend in eine strukturierte Tabellenform überführt:
| ID | Marke | Bezeichnung | Preis | Speicher | Farbe | Zustand |
| 1 | Apple | IPhone 13 | 140€ | 128GB | Rot | gebraucht |
| 2 | Samsung | Galaxy S21 | 310€ | 512GB | Blau | neu |
| 3 | Apple | IPhone 13 | 420€ | 256GB | Gün | gebraucht |
| 4 | Huawei | Pro 30 Lite | 38.000 | 256GB | Schwarz | defekt |
Es wird deutlich, dass strukturierte Daten einfacher zu analysieren sind und somit Informationen leichter zu gewinnen als bei einem unstrukturierten Text.
Nur durch eine solche Eingliederung lassen sich schnell Informationen und Erkenntnisse gewinnen. Solch eine Sammlung von miteinander verknüpften eigenständigen Daten, wird auch als Datensatz bezeichnet. (Quelle: ibm.com)
Wie gezeigt wurde, stellen unstrukturierte Daten eine Herausforderung für die Verarbeitung und Analyse dar, da sie nicht einfach in tabellarische Form umgewandelt oder in relationalen Datenbanken gespeichert werden können.
Die Extraktion von Informationen aus unstrukturierten Daten erfordern spezielle Methoden, wie Textanalyse, Bilderkennung oder Natural Language Processing (NLP).
Diese Techniken werden verwendet, um die Bedeutung und Struktur aus den unstrukturierten Daten zu gewinnen und sie für weitere Analysen oder Entscheidungen nutzbar zu machen.
Das ist aus diesem Grund wichtig zu wissen, da in den letzten Jahren das Wachstum an unstrukturierten Daten, beispielsweise aufgrund der Digitalisierung, der Zunahme von Social-Media-Aktivitäten und Sensordaten, erheblich zugenommen hat.
Zudem wurde aufgrund des Auftretens von Künstlicher Intelligenz das Wachstum nochmals stark beschleunigt, was die Bedeutung von Technologien zur Verarbeitung und Interpretation dieser Art von Daten verstärkt hat.
Beispiele für weitere unstrukturierte Daten sind:
- Textdateien: Freitext, Notizen oder Dokumente ohne bestimmte Formatierung. (auch KI generiert z.B. ChatGPT)
- Bild- und Videodateien: Fotos, Videos oder Audiodateien (auch KI generiert z.B. DALL-E oder Midjourney)
- E-Mails: Eingehende E-Mails mit unterschiedlichen Inhalten und Formatierungen.
- Social-Media-Beiträge: TikTok-Beiträge, Tweets, Instagram-Posts oder andere Social-Media-Inhalte.
- Sensor- und Log-Daten: Rohdaten von Sensoren oder Protokolldateien ohne ein strukturiertes Format.
Semistrukturierte Daten
Was sind nun semistrukturierte Daten? Wie der Name schon verlauten lässt, sind sie eine Art von Daten, die zwischen unstrukturierten und strukturierten Daten liegen.
Im Gegensatz zu strukturierten Daten (z.B. in relationalen Datenbanken) haben semistrukturierte Daten keine festgelegte, allgemeine Struktur, sondern tragen einen Teil der Strukturinformationen mit sich, wie in dem anschließenden Beispiel gezeigt wird.
Sie sind jedoch besser strukturiert als unstrukturierte Daten, was bedeutet, dass sie bestimmte organisatorische Merkmale aufweisen, die eine Verarbeitung und bessere Auswertung ermöglichen.
Ein typisches Beispiel für semistrukturierte Daten ist das Extensible Markup Language (XML). In XML-Dateien können Daten in verschachtelten Tags und Attributen gespeichert werden, wobei nicht alle Elemente den gleichen Satz von Attributen oder Strukturen besitzen müssen.
JSON (JavaScript Object Notation) ist ein weiteres Beispiel für semistrukturierte Daten. JSON verwendet eine ähnliche Baumstruktur mit Schlüssel-Wert-Paaren, die nachfolgend dargestellt sind:

Semistrukturierte Daten bieten größere Flexibilität bei der Datenspeicherung und Übertragung, da sie nicht an ein starres Schema gebunden sind und verschiedene Datenformate unterstützen können.
Allerdings erfordert die Verarbeitung von semistrukturierten Daten spezielle Ansätze, da keine vordefinierten Datenbanktabellen oder festen Beziehungen zwischen den Daten existieren.
Von der Rohdatengewinnung bis zur Analyse – am Beispiel der Suchergebnisseite von Google
Weltweit werden täglich etliche Daten generiert – so auch im Bereich der Suchmaschinenoptimierung (SEO). Zum Abschluss soll an einem praktischen Beispiel der Prozess zur Gewinnung von Rohdaten, über die Verarbeitung bis hin zur Analyse dargestellt werden.
Für Webmaster:innen, Web-Analysten und vor allem SEOs sind die Rankings auf der Suchergebnisseite von Google der wohl interessanteste und wichtigste Faktor.
Aus diesem Grund soll das Ziel sein, das Ranking für ein bestimmtes Keyword im Auge zu behalten und zu analysieren. Hierfür müssen im ersten Schritt Rohdaten gewonnen werden.
Welche Daten werden benötigt?
Beispielhaft sollen täglich, für den Suchbegriff „Sonnenbrille Damen“, die Rankings der ersten Suchergebnisseite beobachtet und analysiert werden. In der nachfolgenden Abbildung ist die Google-SERP (Desktop) für den Suchbegriff „Sonnenbrille Damen“ erkenntlich.
Die SERP bildet dabei die Datenquelle für die anschließende Auswertung:
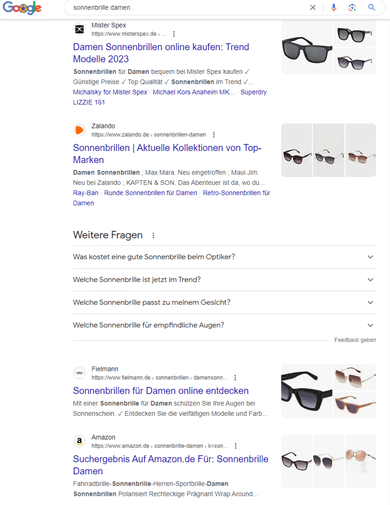
Quelle: Google
Generieren und Speichern der Rohdaten
Im Anschluss muss überlegt werden, wie die Daten gewonnen und abgespeichert werden können. Dabei existieren verschiedene Möglichkeiten für die Datenerhebung.
Von der manuellen Excel-Tabelle, welche händisch befüllt werden muss, bis hin zur automatisierten Scraper Lösung, welche die Daten automatisiert in einer Datenbank hinterlegt.
Unabhängig von dieser Wahl ist es von essenzieller Bedeutung, dass die Daten in einer strukturierten Form vorliegen, um sie auswerten zu können.
Dies stellt aber keine Schwierigkeit dar, da das Ranking einfach per Ziffer hinterlegt werden kann. Zudem werden das Datum und die Website der jeweiligen Position in einer eigenen Spalte hinterlegt.
Beispielhafte Tabelle der Daten
Nachfolgend ist abgebildet, wie die jeweiligen Informationen in einer Datenbank hinterlegt werden können:
| Datum | Position 1 | Position 2 | Position 3 | Position 4 | Position 5 |
| 2023-07-27 | MisterSpex | Zalando | Fielmann | Ray-Ban | Amazon |
| 2023-07-28 | Zalando | MisterSpex | Fielmann | Ray-Ban | Amazon |
| 2023-07-29 | MisterSpex | Zalando | Fielmann | Ray-Ban | Amazon |
Für eine bessere Übersicht sind lediglich die ersten fünf Positionen von drei aufeinanderfolgenden Tagen, des Datensatzes aufgezeigt. Dieses strukturierte Datenschema erlaubt einfache Analysen, aus welchen weitere Erkenntnisse gewonnen werden können.
Analyse der Daten
Um die Primärdaten nun schnell analysieren zu können, werden sie anschließend grafisch aufbereitet. Auch hier gibt es diverse Lösungswege.
Sollten die Daten in einer Excel gespeichert werden, so könnte man mithilfe eines Grafs den Verlauf zeitlich darstellen. Für Daten, welche in einer Datenbank gespeichert werden, könnte beispielsweise Grafana zur Visualisierung verwendet werden.
Das Ergebnis der Datenvisualisierung könnte wie folgt aussehen:
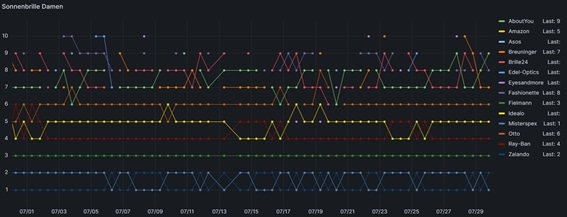
Quelle: eigene Darstellung
Dieses Beispiel soll verdeutlichen, wie mittels Rohdaten, Informationen und Wissen gewonnen werden können.
Rohdaten werden im heutigen Zeitalter immer wichtiger, da laufend neue Daten generiert werden. Aus diesem Grund ist es wichtig zu wissen, welche Daten von Bedeutung sind, wie diese verarbeitet werden müssen und welche Erkenntnisse sich daraus ableiten lassen.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





