
Google stellt die Beachtung der Einträge in der robots.txt neu auf. Seit mehr als 25 Jahren gehört die robots.txt zum Inventar und wurde kaum umgestellt. Dies hat jetzt ein Ende. Google beachtet seit dem 01. September 2019 drei Einträge in der robots.txt nicht mehr.
- noindex
- nofollow
- crawl-delay
Die Verwendung der genannten drei Punkte über die robots.txt fällt zwar weg, kann aber über andere Wege implementiert und verwendet werden. Welche das sind, zeige ich Dir in diesem Artikel.

Noindex – und weg mit der Seite
Im Rahmen der Suchmaschinenoptimierung gibt es immer mal wieder Seiten, Parameter, oder auch Dateiendungen, die nichts im Index zu suchen haben. Über die robots.txt kann hier über ein „Disallow:“ –Statement angegeben werden, was nicht indexiert werden soll. Zudem gibt es noch die drei genannten Tags, die auch häufig genutzt werden und auch funktionieren. Diese Art und Weise ist/war sehr praktikabel, gerade dann, wenn eine komplette Webseite aus dem Index verschwinden sollte. Wer kein CMS nutzt, in dem es eine Funktion zum Ausschluss der Bots gibt, muss alles über die robots.txt lösen. Doch mit der Umstellung wird dies etwas aufwändiger.
Einbindung des noindex Parameters über den <head>-Bereich
Da seit dem 01. September 2019 nicht mehr der Ausschluss über die robots.txt erfolgen kann, gibt es die Möglichkeit zur Einbindung des noindex-Tags über den Header der Webseite. Zunächst muss geklärt werden, was alles vom Index ausgeschlossen werden soll. Wenn die gesamte Webseite aus dem Index gestrichen werden soll, musst Du im <head>-Bereich Deiner Webseite pauschal folgende Eintragung machen: <meta name=”robots” content=”noindex” />. Solltest Du aber nur einzelne Unterseiten aussperren, dann ist es nötig, über z. B. PHP-Abfragen die gewünschte Seite ausfindig zu machen und darauf das genannte Tag zeigen lassen. Am einfachsten geht es natürlich, wenn Du ein CMS verwendest. In den Content-Management-Systemen gibt es die Möglichkeit, Seiten einzeln zu markieren, die von der Indexierung ausgeschlossen werden sollen.
Noindex über den X-Robots-Tag-HTTP-Header
Du hast auch die Möglichkeit Deine Seite über den X-Robots-Tag im HTTP-Header mit noindex zu versorgen. Jede Anweisung, die Du über den Head-Bereich machst, kannst Du auch mit dieser Variante erledigen. Hierzu musst Du Einstellungen an Deiner header.php vornehmen. Damit die Seite aus dem Index entfernt wird, muss folgende Anweisung in Deiner header.php eingetragen werden: header(“X-Robots-Tag: noindex”, true);
Wenn Du allerdings auch möchtest, dass allen Links nicht gefolgt wird, dann sieht die Anweisung folgendermaßen aus: header(“X-Robots-Tag: noindex, nofollow”, true);
Ausschluss von Dateiendungen über den X-Robots-Tag in der .htaccess
Damit Du auch weiterhin Dateiendungen aus dem Index halten kannst, was Du ja bisher über ein Disallow in der robots.txt gemacht hast, gibt es hierfür auch eine praktikable Lösung. Die Lösung bietet hier die .htaccess auf Deinem Apache- oder NGINX-Server. Du hast die Möglichkeit eine Dateiendung oder aber in einem Statement sogar mehrere Dateiendungen vom Index auszuschließen. Die Anweisung zum Ausschluss von .pdf-Dateien lautet wie folgt:
Lösung für Apache (.pdf)
<FilesMatch “.pdf$”>
Header set X-Robots-Tag “noindex, noarchive, nosnippet”
</FilesMatch>
Damit nun weitere Dateiendungen aus dem Index verschwinden können, kann ganz einfach mithilfe einer Pipe „|“ die Liste beliebig erweitert werden. Sollten nicht nur .pdf-Dateien, sondern auch Dateien der Endungen docx, xlsx, png aus dem Index gelöscht werden, dann muss folgendes Codesnippet in der .htaccess untergebracht werden:
Lösung für Apache (merhere Dateiendungen)
<FilesMatch “.(pdf|docx|xlsx|png|jpg)$”>
Header set X-Robots-Tag “noindex, noarchive, nosnippet”
</FilesMatch>
[magazin_teaser]
Für NGINX-Server gibt es auch eine Lösung:
location ~* \.(pdf|docx|png)$ {
add_header X-Robots-Tag “noindex, noarchive, nosnippet”;
}
Entfernen von URLs mit Hilfe der Google Search Console
Wenn Du nicht weißt, wie Du das alles umsetzen sollst, kannst Du auch über die Google Search Console gehen und die gewünschten URLs aus dem Index manövrieren. Die Funktion zur Entfernung von URLs aus dem Index ist momentan noch in der alten GSC vorhanden. Hierzu gehst Du auf den Punkt Google Index → URLs entfernen und klickst auf „Vorübergehend ausblenden“.
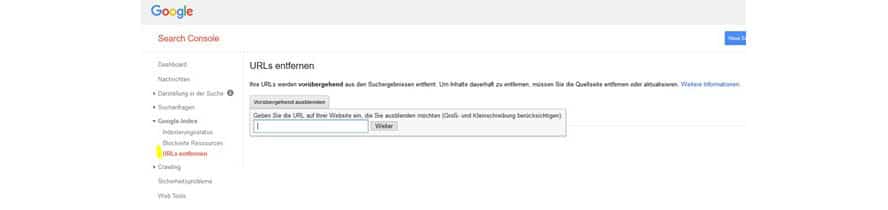
Mit Hilfe der Google Search Console lassen sich auf einfache Art und Weise URLs aus dem Index entfernen.
Diese Einstellung unterdrückt nur eine gewisse Zeit die Seite für den Index. Dennoch ist diese praktikabel und sollte zumindest so lange verwendet werden, bis Du Dich endgültig dazu entschieden hast, was mit einer Seite geschehen soll. Wenn Du die Unterseite die entfernt werden soll, endgültig abstellst, leite diese URL bitte auf eine passende andere weiter. Solltest Du keine passende Kategorie dafür haben, dann kannst Du diese URL auch auf die Startseite per 301-Weiterleitung umleiten.
Nofollow sagt adieu!
Neben noindex wird auch nofollow nicht mehr über die robots.txt zur Anwendung kommen. Aber auch hier gibt es dank dem Meta-Robots-Tag und dem X-Robot-Tag im http-Header Abhilfe. Nofollow dient dazu, dass die nachfolgenden Links nicht von der Suchmaschine gefolgt und weiter erfasst werden sollen.
Nofollow im <head>-Bereich
Die Einbindung von nofollow über den <head>-Bereich einer Seite ist recht einfach. Hierzu muss nur der folgende Meta-Robots-Tag eingefügt werden:
<meta name=”robots” content=”nofollow” />.
Nofollow im http-Header
Eine weitere Möglichkeit zu Einbindung von nofollow, nach der Umstellung der robots.txt, ist die Zugabe des Parameters in den http-Header. Um die nofollow-Einstellung einzubinden, musst Du die Datei öffnen, in der sich Dein <head>-Bereich befindet. Bei den meisten Systemen gibt es hierfür die header.php. In dieser Datei platzierst Du wie schon weiter oben beschrieben den nachfolgenden Tag:
header(“X-Robots-Tag: nofollow”, true);
Das Aus für den Crawl-Delay
Der Crawl-Delay ist eine Erweiterung, die von Microsoft und Yahoo ins Leben gerufen wurde. Die Anweisung sollte dazu dienen, wie oft der Crawler eine Webseite besuchen soll. Wenn der Crawl-Delay auf 60 eingestellt wurde, bedeutet dies, dass alle 60 Sekunden der Bot vorbeikommen soll und eine Seite zur Indexierung mitnehmen soll. Wichtig ist hierbei zu beachten, dass bei einem Crawl-Delay von 60 maximal 1.440 Seiten pro Tag indexiert werden können. Bei Webseiten, die mehrere Tausend Einträge haben musste hier ein kleinerer Wert gewählt werden, damit die SERPs immer aktuell bleiben.

Fazit
Nach einem Vierteljahrhundert wird das Internet nicht neu erfunden, dafür aber veraltete Zöpfe abgeschnitten. Die Verwendung von noindex und nofollow wird heute in den meisten Fällen direkt über den <head>-Bereich der Webseite gelöst. Arbeitet in der robots.txt mit dem bekannten „Disallow“-Parameter zum Ausschluss von Verzeichnissen, Seiten, oder auch Parametern.
Zudem könnt Ihr auch über die robots.txt Dateiendungen ausschließen. Mit Disallow: /*.pdf$, oder Disallow: /*.xlsx$ kannst Du beispielsweise PDF- oder Excel-Dateien aus dem Index befördern. Die Anweisungen kannst Du für jegliche Dateiendungen verwenden, die ausgeschlossen werden sollen. Mache Dir hier genau Gedanken, welche Dateitypen Du auf Deiner Webseite hast und welche Du in den Index befördern möchtest. Ich rate Dir dazu, PDF-Dateien immer aus dem Index auszusperren, da Du Dir hier in den meisten Fällen Duplicate Content schaffst.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





