
Crawling und Indexierung sind Kerndisziplinen in der Suchmaschinenoptimierung. Deshalb ist es essenziell, dass das Crawlen der Webseite reibungslos funktioniert, um so zu mehr SEO-Erfolg zu führen.
Google gestaltet das Crawling immer nachhaltiger und möchte nur noch so oft wie nötig URLs und Inhalte crawlen. Umso wichtiger ist es, das verfügbare Crawl Budget einer Domain effizient zu nutzen, um es voll auszuschöpfen. Aber wie kann man das verfügbare Crawl Budget erhöhen und wie kann man sparsamer damit umgehen?
Crawl Budget – Was ist das überhaupt?
Damit Inhalte einer Webseite in den Suchmaschinenindex aufgenommen werden, müssen sie von den Bots der Suchmaschinen gecrawlt und indexiert werden.
Da der Googlebot nur begrenzt Zeit hat, eine Webseite zu crawlen, beschreibt Google das Crawl Budget als „die Zeit und die Ressourcen, die Google für das Crawling einer Webseite aufwendet“.
Dieses wird durch zwei Begriffe bestimmt:
- Crawling-Kapazitätslimit
- Crawling-Bedarf
Das Crawling-Kapazitätslimit ist hauptsächlich von technischen Faktoren abhängig. Hier wird bestimmt, wie viele Verbindungen der Googlebot für das Crawlen einer Webseite nutzen kann und wie viel Zeit zwischen den einzelnen Crawls der URLs vergeht. Das Kapazitätslimit hängt also maßgeblich von der Seitengeschwindigkeit ab.
Der Crawling-Bedarf hingegen versucht einzuschätzen, wie oft die Inhalte überhaupt gecrawlt werden müssen. Das ist insbesondere von der Qualität des Contents der Webseite abhängig, aber auch von den Statuscodes der zu crawlenden URLs. Logischerweise verringern viele 404-Seiten den Crawling-Bedarf, da sie für die Nutzer keinen Mehrwert bieten. Auch andere Fehlercodes, wie 3xx oder 5xx verringern den Crawling-Bedarf.
Ebenso können Dateien ohne Mehrwert für den Nutzer einen negativen Einfluss haben.
Auch die generelle Popularität von Inhalten im Internet, z. B. gemessen an Backlinks ist ein wesentlicher Einflussfaktor und hilft Google einzuschätzen, wie groß der Bedarf ist. Kurz gesagt bestimmt das Crawling Budget, wie viele URLs einer Webseite der Bot durchschnittlich pro Tag crawlt.
Status-quo-Analyse des Crawl Budgets einer Webseite
Wie viel Crawl Budget stellt Google derzeit für die eigene Webseite bereit? Um das herauszufinden, erweist sich die Google Search Console für Webseitenbetreiber als hilfreiches Tool.
So gelangst Du in der Search Console zu den Crawling-Statistiken:
Vorherige Tools und Berichte -> Einstellungen -> Crawling-Statistiken
An den Crawling-Statistiken lässt sich beispielsweise genau erkennen, wie viele URLs in den letzten 90 Tagen pro Tag gecrawlt wurden (Abbildung 1 – Crawling-Anfragen in der GSC). Da der Zeitraum sich nicht verstellen lässt, lohnt es sich, regelmäßig einen Blick in die Crawling-Statistiken zu werfen.
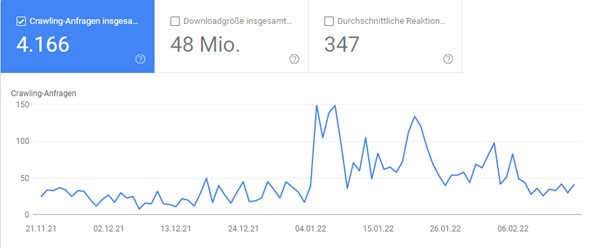
Crawling-Anfragen in der GSC.
Neben der Anzahl an gecrawlten URLs lässt sich hier auch bereits erkennen, ob es Unregelmäßigkeiten im Crawling-Verhalten der Webseite gibt. Dafür gibt es zum Beispiel den Bericht – aufgeschlüsselt nach Antworten. Idealerweise sollte hier der Anteil an 200er-Statuscodes möglichst nah an die 100 % heranreichen.
Gibt es hier besonders viele Weiterleitungen, 404-Fehler oder 500er-Serverfehler, besteht in jedem Fall dringender Handlungsbedarf.
Auf Abbildung 2 lässt sich erkennen, dass enorm viele Weiterleitungen gecrawlt werden und dafür über 10 % des Crawl Budgets verwendet werden. Auch die 404-Fehler sind mit 5 % recht hoch und verhindern ein effizientes Crawling der betrachteten Webseite.
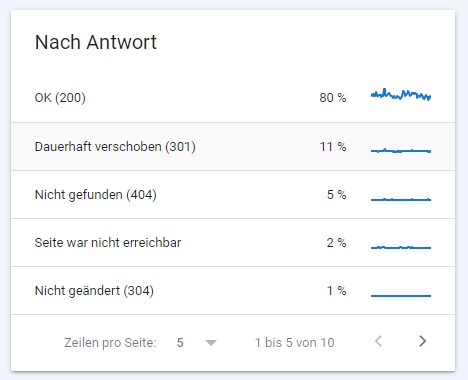
Antworten der gecrawlten URLs.
Aber auch ein großer Anteil von 200er-Seiten heißt nicht automatisch, dass das Crawl Budget effizient genutzt wird, denn es gibt häufig eine Vielzahl an Seiten und Unterseiten, die trotz Verfügbarkeit nicht für das Crawling relevant sind.
Duplicate und Thin Content
Neben all den Seiten, die aufgrund falscher Statuscodes das Crawling unnötig strapazieren, können sich auch schlechte oder zu wenig Inhalte auf einer Seite negativ auswirken.
Ganz ähnlich sieht es mit Duplicate Content aus. Stößt der Googlebot auf die immer gleichen Inhalte bei verschiedenen und eventuell sogar indexierbaren URLs, kann dies sogar dazu führen, dass Google der gesamten Webseite in Zukunft weniger Crawl Budget zur Verfügung stellt.
Folglich sollten Seiten mit minderwertigem Inhalt entfernt oder vom Crawling ausgeschlossen werden und Duplicate Content per Canonical Tag auf sein indexierbares Original verweisen, um so Google klare Signale zu geben.
Nicht crawling-relevante Seiten
Eine Webseite kann viele URLs haben. Beispielsweise können Shops für Bekleidung durch Filtermöglichkeiten auf den Kategorieseiten nahezu unendlich viele Unterseiten kreieren.
Auf Abbildung 3 ist zu sehen, wie viele Filter Nutzer setzen können, wobei jede Kombination von Filtern eine URL generiert. Allein für die verfügbaren Farben der Kleidungsstücke gibt es dementsprechend 16 URLs. Hinzu kommt, dass sich auch mehrere Farben gleichzeitig auswählen lassen.
Dasselbe gilt für Größe, Marke, Preis, Material und viele weitere Optionen, die sich wiederum miteinander kombinieren lassen. Allein die Kategorieseite für Pullover und Strickmode erzeugt bereits so viele URLs, dass diese schon fast das gesamte Crawl Budget aufbrauchen könnten.
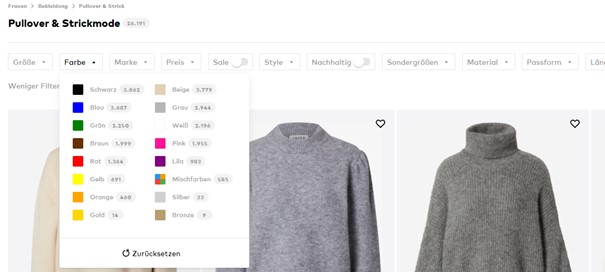
Kategorieseite mit Filteroptionen
Um das zu verhindern, sollten URLs, die fürs Crawling nicht relevant sind, vom Crawling ausgeschlossen werden. Es gilt abzuwägen, inwieweit bestimmte URLs crawling- und rankingrelevant sind. Keywords wie „graue pullover“ oder „pullover grau“ haben genügend Suchvolumen, dass es sich lohnt, diese Seiten zu indexieren und folglich auch vom Googlebot crawlen zu lassen.
In Kombination mit weiteren Filtermöglichkeiten weisen sie aber eher wenig bis gar kein Suchvolumen auf und brauchen somit nicht indexiert und gecrawlt werden. Das Crawling einer Webseite lässt sich durch viele verschiedene Möglichkeiten, wie interne Verlinkung und das Blockieren von Verzeichnissen oder einzelnen URLs steuern.
Am effektivsten lassen sich Filter-URLs (wie die aus dem Beispiel) per Linkmaskierung vom Crawling ausschließen.
Linkmaskierung via PRG Pattern
Sind Links für den Nutzer erforderlich, sollen für den Crawler aber unzugänglich gemacht werden, kannst Du das mit dem PRG Pattern (PRG = Post/Redirect/Get) erreichen.
Eine reine Verschlüsselung reicht nicht aus, da viele Crawler eine base64-Codierung entschlüsseln können. Deswegen ist es wichtig, entsprechende Links mit einer Kombination aus Verschlüsselung und PRG Pattern zu maskieren. Somit ist der Link für den Bot nicht auffindbar, für den Nutzer aber schon.
Beispiel HTML-Code:

Beispielcode für Kombination aus Verschlüsselung und PRG Pattern.
Der Nutzer kann auf einen Button klicken und kommt zur nächsten Seite, während der Bot dem Link nicht folgen kann.
Aber wie genau funktioniert das PRG Pattern?
Das Prinzip ist, dass hier anstelle eines Links ein Formular im Quellcode eingebunden wird.
- Klickt der Nutzer auf den (visuellen) „Link“, wird ein POST-Request an den Server gesendet. Dieser teilt dem Server mit, welche URL ein Nutzer aufrufen möchte.
- Daraufhin verarbeitet der Server den Request und leitet einen normalen Nutzer per REDIRECT (Status Code 303 – See Other) auf die gewünschte Ziel-URL weiter.
- Der Client / Browser fordert nun per GET-Request die Ziel-URL beim Server an, woraufhin dieser die Zielseite mit Statuscode 200 an den Client schickt.
Durch diese Umsetzung wird das Crawl Budget für nicht crawlingrelevante URLs nicht unnötig belastet, da der Googlebot keine POST-Requests senden kann und die verlinkte URL somit für Google nicht auffindbar ist.
Technische Vorgehensweise PRG-Pattern
- Auf jeder Seite existiert ein verstecktes (display: none bzw. visibility: 0) Formular-Element und ein unsichtbares (hidden) input-Element.
- Die Übertragungsmethode des Formulars muss auf „POST“ eingestellt sein. Das Formular wird auf eine vordefinierte URL verschickt, unter der ein serverseitiges Skript zum Bearbeiten der Requests läuft.
- Das Input-Feld hat keinen Wert (value=““).
- Maskierte Links werden im HTML als span-Elemente dargestellt und per CSS als Link nachempfunden. In einem Attribut (z. B. data-submit) enthält jedes span-Element die base64-codierte Ziel-URL.
- Ein Klick auf einen maskierten Link wird per JavaScript onclick-Event abgefangen. Die base64-codierte Ziel-URL wird aus dem jeweiligen Attribut ausgelesen und als Wert in das input-Feld eingefügt. Das Formular wird dann per JavaScript submit-Event abgeschickt.
- Das serverseitige Skript empfängt die PRG-Requests, decodiert die base64-codierte Ziel-URL und erzeugt einen 303-Redirect auf die decodierte Ziel-URL.
Um sicherzustellen, dass der Googlebot diese maskierten Links tatsächlich nicht aufruft, kann man im serverseitigen Skript zusätzlich eine if-Schleife einbauen, die den User Agent überprüft. Sollte es sich dann um den Agent „Googlebot“ handeln, wird die Codierung des base64 gar nicht erst gestartet, sondern das Skript zum Codieren umgehend beendet.
Unbedingt zu beachten ist außerdem, dass die maskierten Links nicht an anderen Stellen ohne Maskierung verlinkt werden, da sonst der gesamte Prozess der Linkmaskierung vergebens ist.
Es ist auch möglich, ganze Verzeichnisse oder bestimmte Dateitypen auf anderem Wege für den Crawler zu blockieren.
Verzeichnisse blockieren in der robots.txt der Webseite
Im root-Verzeichnis jeder Webseite sollte die robots.txt liegen. Hier können bestimmte Verzeichnisse für verschiedene Crawling-Bots blockiert werden. Es müssen lediglich der User Agent festgelegt (* für alle User Agents) und die zu blockierenden Verzeichnisse per „Disallow“-Befehl eingetragen werden.
Wie so eine robots.txt aussieht, zeigt Abbildung 5 am Beispiel der derzeitigen robots.txt von Zalando DE.
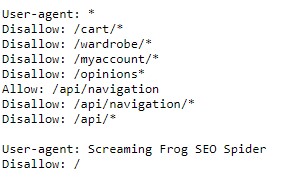
robots.txt von Zalando DE.
Das Blockieren der Verzeichnisse muss immer Hand in Hand mit der internen Verlinkung gehen. Denn wenn der Googlebot Links zu den entsprechenden URLs findet, kann es trotzdem zu einer Indexierung kommen.
Ist eine URL im blockierten Verzeichnis beispielsweise sehr häufig intern verlinkt, stuft Google diese URLs als wichtig ein und nimmt sie möglicherweise in den Google-Index auf, ohne sie jemals gecrawlt zu haben.
Das Crawl-Verhalten des Googlebots kann auch mit Crawling-Tools wie Screaming Frog, Sitebulb, Ryte und anderen simuliert werden. So lässt sich überprüfen, ob die Linkmaskierungen und die blockierten Verzeichnisse in der robots.txt ordnungsgemäß funktionieren und ob es Broken Links gibt.
Broken Links identifizieren mit Screaming Frog
Broken Links einer Webseite lassen sich mit vielen Tools aufspüren. Eines der populärsten Tools dafür ist das Crawling-Tool Screaming Frog.
Das Vorgehen hierfür ist denkbar einfach: die gesamte Webseite crawlen und – wichtig – die Internal Hyperlinks erfassen. Die entsprechende Einstellung ist in Abbildung 6 zu sehen.
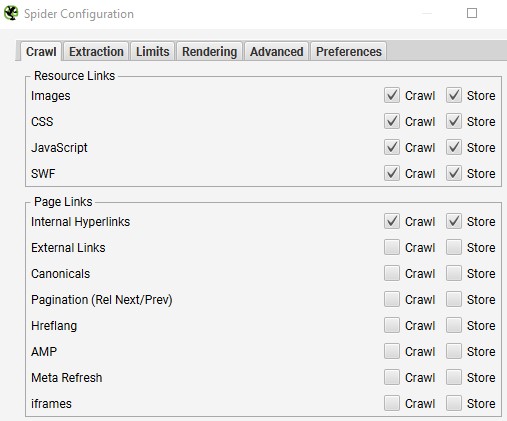
Screaming Frog Crawl Settings
Es bietet sich an, die Resource Links mit in den Crawl aufzunehmen, da sie ebenso von Broken Links betroffen sein können. Die weiteren Page Links sind für die Identifizierung von Broken Links zu vernachlässigen, um den Crawl nicht unnötig aufzublähen.
Ist der Crawl abgeschlossen, werden folgende Exports benötigt:
Reports -> Redirects -> All Redirects
Bulk Exports -> Response Codes -> Client Error (4xx) Inlinks
Bulk Exports -> Response Codes -> Server Error (5xx) Inlinks
An den Tabellen lässt sich ablesen, welche URLs einen 3xx-, 4xx- oder 5xx-Statuscode zurückgeben. Außerdem ist es möglich herauszufinden, welche die verlinkende URL ist und in welchem Element der fehlerhafte Link platziert ist.
Daraus resultierend sollten 4xx- und 5xx-Links entweder gelöscht oder durch andere sinngemäße Linkziele ersetzt werden.
Aus dem All Redirects Export können wir zudem das finale Weiterleitungsziel ablesen. Hier sollte nur die 3xx-URL mit dem finalen Weiterleitungsziel ausgetauscht werden. Gemessen am Beispiel aus Abbildung 2 sparen wir schon mit dieser einfachen Methode und überschaubarem Aufwand eine große Menge an verschwendetem Crawl Budget ein, welches somit für die Erfassung und Aktualisierung von wirklich SEO-relevanten URLs frei wird.
Doch, welche weiteren Schritte sind nötig, um das Crawl Budget optimal zu nutzen?
Mit interner Verlinkung und flacher Seitenhierarchie dem Bot den Weg ebnen
Um dem Googlebot das Crawlen aller relevanten URLs zu ermöglichen, sollten diese mit wenigen Klicks erreichbar sein.
Deshalb ist eine optimierte Seitenarchitektur wichtig. Je flacher die Seitenhierarchie einer Webseite ist, desto besser.
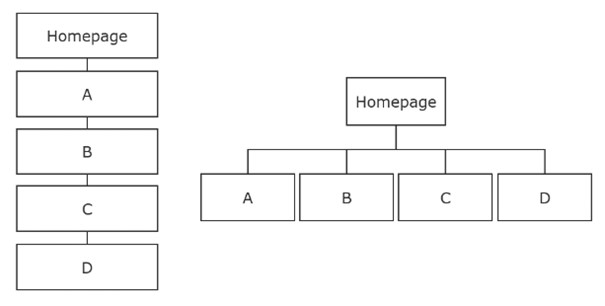
Tiefe vs. flache Seitenhierarchie.
Die flache Seitenhierarchie in Abbildung 7 verdeutlicht, dass der Googlebot leichter alle Zielseiten aufrufen kann, wenn er sie jeweils mit nur einem einzigen Klick erreicht. Bei der tiefen Seitenhierarchie hingegen braucht der Bot vier Klicks, um zu Seite D zu gelangen.
Auch für die Gewichtung der einzelnen Seiten ist eine flache Hierarchie wichtig, denn je mehr Klicks der Bot braucht, desto unwichtiger schätzt er diese Zielseite und deren Inhalt ein.
Bei der Verlinkung ist auch zu beachten, dass der Googlebot beim Crawlen nicht in eine Sackgasse gerät. Stattdessen sollte er von jeder Seite möglichst viele Links zu anderen relevanten und wichtigen Zielseiten aufrufen können.
Es ist also sinnvoll, die URLs einer Webseite – je nach Wichtigkeit – öfter intern zu verlinken, um so die interne Linkstruktur zu stärken.
Um sicherzustellen, dass der Googlebot die wichtigsten URLs findet, ist außerdem das Einreichen einer Sitemap essenziell. Wird eine Sitemap an Google übermittelt, ist gewährleistet, dass alle dort aufgenommenen URLs auf jeden Fall gecrawlt werden.
Deswegen ist es wichtig, hier nur URLs aufzunehmen, die von Google sowohl gecrawlt als auch indexiert werden sollen. Das eigene Crawl Budget möglichst effizient zu nutzen, ist ein Ansatz – der andere ist, es zu erhöhen.
Crawl Budget erhöhen durch aktualisierten Content und schnellere Ladezeit
Stellt Google fest, dass der Inhalt einer Webseite oft aktualisiert wird, wird der Googlebot in den meisten Fällen auch öfter zum Crawlen wiederkehren, um diese Änderungen stets zeitnah zu erfassen.
Es lohnt sich also, Artikel regelmäßig zu updaten. Hier sollte aber auf Tricksereien – etwa das Ändern eines einzigen Worts oder des Datums – verzichten werden. Es ist anzunehmen, dass Google mittlerweile nachvollziehen kann, wann der Content so maßgeblich verändert wurde, dass ein erneutes Crawlen und Indexieren notwendig sind.
Des Weiteren spielt die Ladezeit der Seiten eine wichtige Rolle. Je schneller der Googlebot eine Seite lesen und rendern kann, desto mehr URLs können in einem bestimmten Zeitraum gecrawlt werden. Eine höhere Seitenladegeschwindigkeit kann also ein höheres Crawl Budget bedeuten.
Fazit
Wie effizient Du das eigene Crawl Budget nutzt und ob es sich sogar steigern lässt, hängt von vielen Faktoren ab. Mit den hier genannten Maßnahmen ist es Webseitenbetreibern möglich, das verfügbare Crawl Budget besser zu nutzen und alle SEO-relevanten URLs abzudecken.
Da das Crawlen von unzähligen Webseiten ressourcenintensiv ist, wird Google in Zukunft Crawl Budget sparsamer vergeben – jede URL, die nicht unnötig gecrawlt wird, spart wichtige Ressourcen ein. Gerade vor diesem Hintergrund ist die Optimierung des eigenen Crawl Budgets essenziell.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen






Super spannender Artikel, und doch hinterlässt er ein paar Fragen bei mir: 1. Was bedeutet flache Seitenhierarchie genau, also was schaut sich der Bot an? Wenn ich eine flyout-Navigation habe mit Links auf Dokumente, die ich gerne sichtbar machen möchte für den Kunden, dann kann er diese mit dem 2 Klick erreichen. Wenn das Dokument aber im backend auf Ebene 7 liegt (Verzeichnis/Ordner), was zählt dann? Klickt der Bot wie der Kunde oder schaut er sich die Ebenen an, auf denen die Dokumente liegen? Oder anders ausgedrückt: zählt der Baum im backend oder die Usability und Führung live auf der… Weiterlesen »
Hallo Natalie, Es zählt die Klicktiefe. Der Bot klickt sich hierbei wie der User durch die Links einer Seite (nach dem Reasonable Surfer Model). Die Verzeichnisebene ist also nicht entscheidend. In der Sitemap sollten alle URLs gelistet werden die durch die Suchmaschine indexiert werden sollen. Hier können natürlich auch mehrere Sitemaps angelegt werden. Wenn du eine Seite deindexieren lassen möchtest, sollte der Meta Robots Tag auf “noindex” gesetzt werden. Beim nächsten Crawling der URL wird diese Seite dann aus dem Index verschwinden. Sollte so eine URL vom Crawling bereits ausgeschlossen sein, ist es wichtig sie wieder crawlbar zu machen, damit… Weiterlesen »