
Was ist Filterindexierung?
Mit dem Begriff Filterindexierung (ähnlich Filternavigation) wird im SEO die Entscheidung zur Indexierung, also Aufnahme in Suchmaschinen einzelner URLs beschrieben.
Entscheidend in diesem Zusammenhang ist die Existenz von Suchnachfrage der so gefilterten Kategorie- oder Archivseiten.
Als UX-Element dient die Filternavigation außerdem als wichtiges Seitenelement, um Nutzern und Nutzerinnen das Finden passender Produkte zu erleichtern.

Für welche Webseiten ist Filterindexierung relevant?
Relativ häufig wird unterstellt, dass die Indizierung von Filterseiten nur E-Commerce-Webseiten betrifft, vor allem Onlineshops. Tatsächlich profitieren aber alle Webseiten mit sehr großem URL-Inventar (v.a. in Form von Artikeln, Produkten) davon, dieses für Nutzer:innen gut durchsuchbar zu machen.
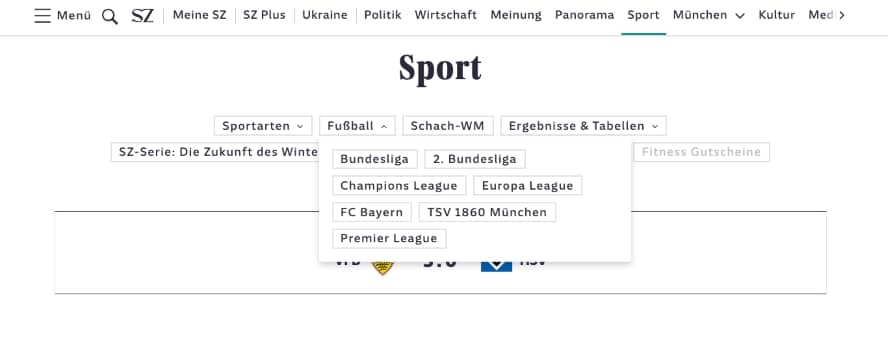
Auch die Süddeutsche Zeitung setzt auf die Facettierung ihrer umfangreichen Inhalte.
In der Regel obliegt es aber dem SEO, zu entscheiden, welche dieser Filterseiten ein relevantes Thema darstellt. Die geeigneten Metriken hierfür: Suchvolumen + ausreichend Inventar:
- Suchvolumen: Ab einem individuellen Grenzwert wird die Entscheidung für die Filterindexierung getroffen.
- ∑ Inventar: Nutzern und Nutzerinnen Filterseiten ohne Inhalt zu präsentieren ist nicht sinnvoll. Deshalb resultieren z.B. Shop-Filterseiten ohne Produkte relativ schnell in Rankingverlusten (siehe „ESN-Case”) oder werden nicht ranken.
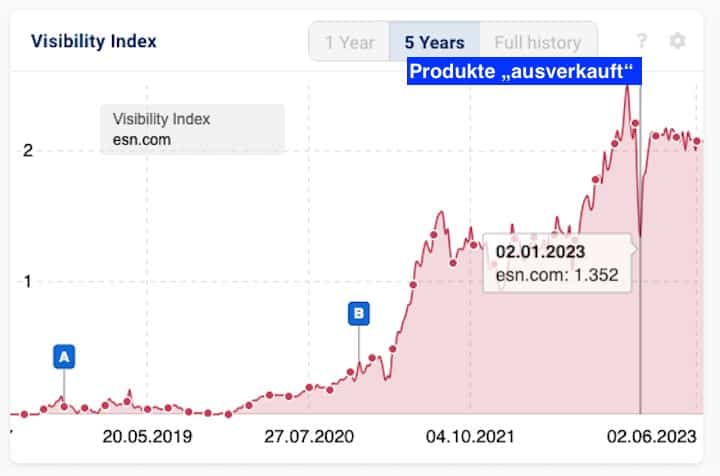
ESN-Case: Kurzzeitig Produkte aus Shop „entfernt”
Ende 2022 setzte der Nahrungsergänzungsmittelhändler „ESN” in seinem Shop aus logistischen Herausforderungen (Auslieferung von Bestellungen) alle Produkte auf „ausverkauft”.
Google reagierte schnell und ersetzte gut rankende ESN-URLs mit denen von Mitbewerbern. Gut zu sehen am Verlauf des Sichtbarkeitsverlaufes der Domain.
ESN Sichtbarkeitsverlauf lt. sistrix.de zum Zeitpunkt des komplett „ausverkauften Inventars“. Deutlich ist der Einbruch der Sichtbarkeit zu erkennen:
Potenzial fehlender Filterindexierung
Klassischerweise sind vor allem die Kategorienseiten in Onlineshops für einen Großteil des akquirierten, organischen Suchmaschinen-Traffics verantwortlich.
In der Regel verfügt selbst ein Shop am Anfang seiner Lebensdauer über einen rudimentären Kategoriebaum, durch dessen Hilfe das vorhandene Inventar auch in Unterkategorien segmentiert wird.
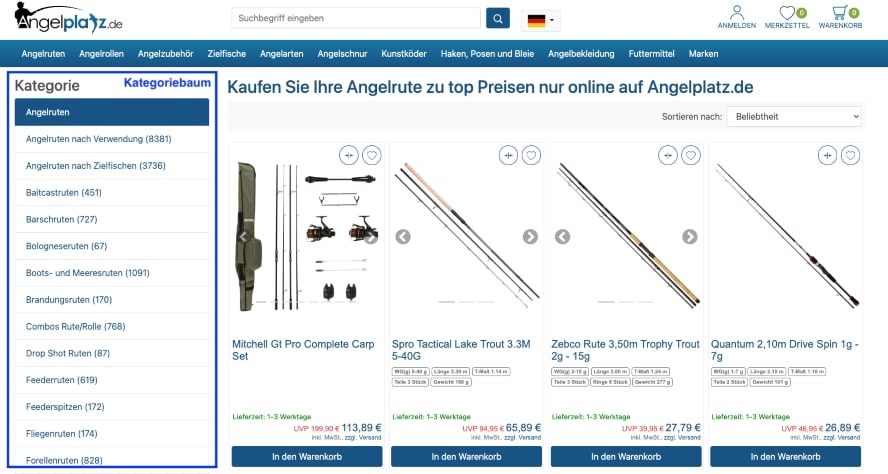
Angelplatz.de segmentiert das eigene Sortiment über die Darstellung der Kategorisierung, auch Kategoriebaum genannt.
Mit dieser Struktur und indexieren dieser Seiten lässt sich für jeden Onlineshop bereits eine große Menge an Suchvolumen und final auch Traffic gewinnen.
Allerdings wird man mit diesen Seiten nur einem Teil des potenziell bedienbaren Keyword-Sets gerecht. Es kann davon ausgegangen werden, dass man auf diese Weise nur zu Short-Tail Keywords ranken wird, wie z.B. “Hosen”, “Zelte” oder “Fernseher”.
Zu sehr spezifischen Suchtermen, mit gleichzeitig relevanter Nachfrage, wird man mit Haupt- und Unterkategorieseiten keine großen Chancen auf prominente Rankings bekommen.
Die Nichterfüllung der Nutzerintention spielt hierbei die größte Rolle, aber auch technische (Hygiene-)Faktoren, wie fehlende Relevanz in Onpage-Element durch passende Title oder Überschriften.
So beinhaltet die Suchergebnisseite (SERP) zum Thema “boxspringbetten 180×200” 80 % spezifische URLs, die in allen Onpage-Elementen dieses Thema integriert haben:
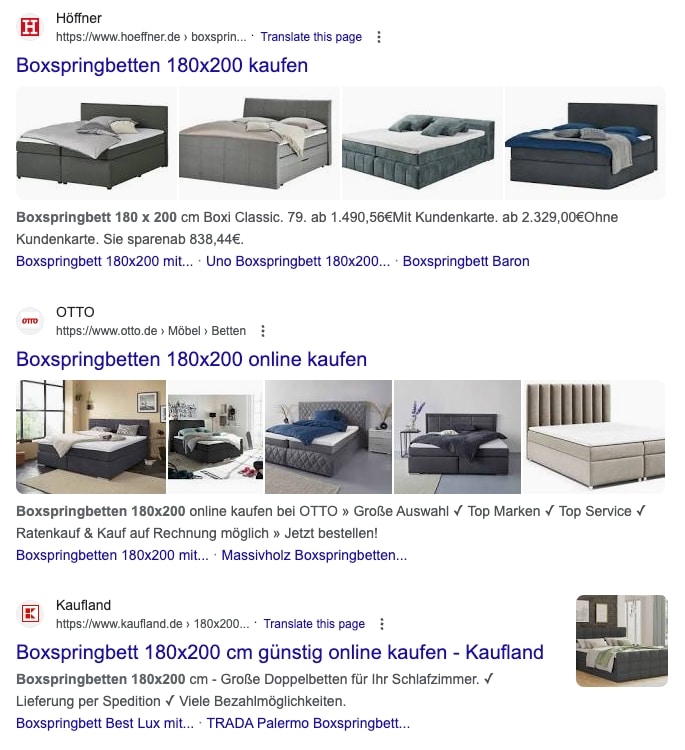
Sicht auf die Top 3 organischen Ergebnisse zum Suchbegriff „Boxspringbett 180×200”. Hier wird deutlich, dass nur spezifisch darauf optimierte URLs ranken.
Um also dieses Potenzial mit einer möglichst hohen Wahrscheinlichkeit erschließen zu können, führt kein Weg an der Filterindexierung vorbei.
1. Wie hoch kann das Potenzial der Filterindexierung sein?
2. Interne Verlinkung konzipieren
3. Onpage-Optimierung bei Filterindexierung
Wie hoch kann das Potenzial der Filterindexierung sein?
Ob sich eine Filterindexierung lohnt, ist sehr stark von der Nachfrage der relevanten Hauptkategorie abhängig. Je höher das Suchvolumen dieser Kategorien ist, desto wahrscheinlicher finden sich durch Filterseiten abzudeckende Themen.
Beispiel:
- Hauptkeyword „Pullover” hat ca. 480k Suchvolumen p.a.
- Facetten-Begriffe wie „lange Pullover”, „weiße Pullover” usw. besitzen ein SV von knapp 270k Suchvolumen p.a.
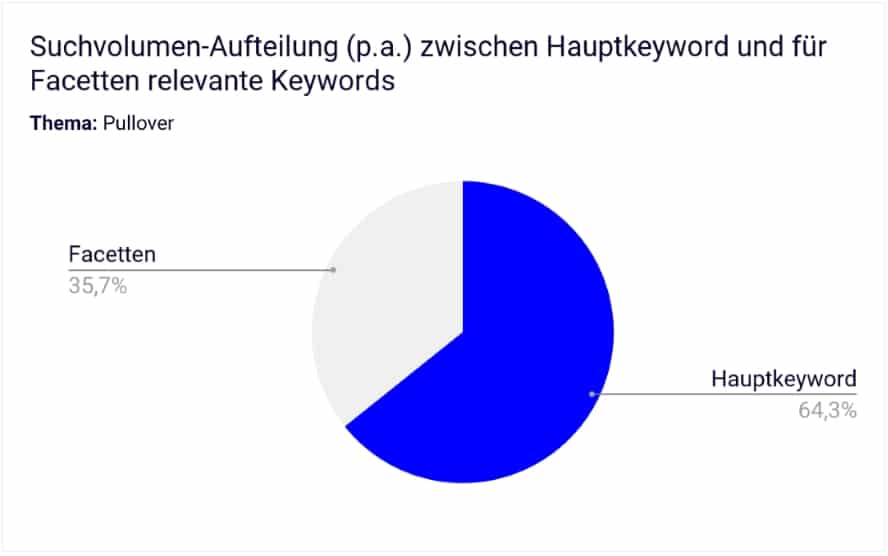
Potenzialdarstellung von für Facetten geeigneten Keywords im Vergleich zum Hauptkeyword.
Die in diesem Beispiel durch Filterseiten bedienbare Nachfrage liegt bei zusätzlichen >55 % des Suchvolumens zum Hauptkeyword. Vermutlich ist die tatsächliche Summe deutlich höher.
Aus der Erfahrung heraus sorgt die Filterindexierung dafür, dass langfristig mindestens 20 % des Non-Brand SEO-Traffics mit diesen URLs gewonnen werden können.
Das zeigt, welches Potenzial in der gezielten Filterindexierung steckt und weshalb man diese nicht nur für Nutzer:innen, sondern auch für Suchmaschinen zugänglich machen sollte.
Interne Verlinkung konzipieren
Die neu entstehenden URLs wären ohne auf sie verweisende, interne Links chancenlos. Weder würden sie nachhaltig und schnell durch Suchmaschinen entdeckt werden, noch hätten sie genug interne „Rankingkraft”, um sich gegen die Konkurrenz in den Suchergebnissen durchzusetzen.
Initial sollte es also vor allem darum gehen, überhaupt interne Links zu diesen Seiten aufzubauen. Dabei sollte man prinzipiell programmatische und automatisierte Lösungen wählen, wie die folgenden:
Direkte Verlinkung aus Filternavigation
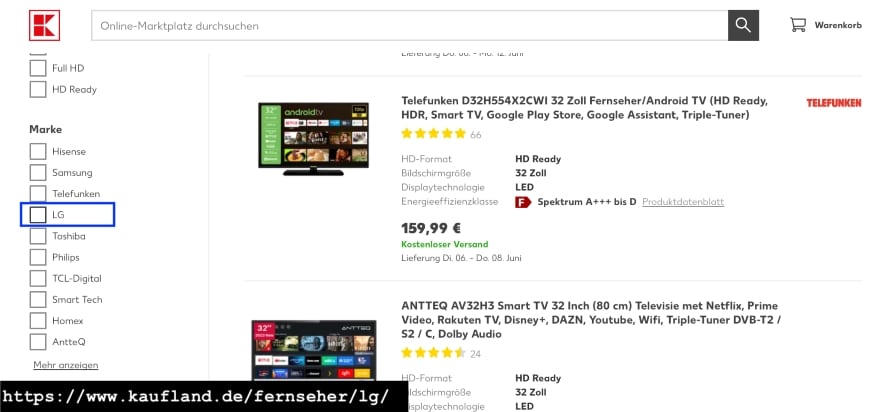
Direkte Verlinkung aus dem Filterbereich bei kaufland.de
Wie im Screenshot zu sehen, werden die für die Filterindexierung relevanten Seiten aus der Filternavigation verlinkt. Um das funktionelle UX-Element wird also ein <a href=”…”> gebunden und so die Zielseite (in diesem Fall https://www.kaufland.de/fernseher/lg/) direkt verlinkt.
Diese Lösung ist in sehr vielen Fällen die einfachste Variante, um nachhaltig und strukturiert Filterseiten zu verlinken.
Einziger Wermutstropfen sind in der Regel die Linktexte, die kaum thematische Relevanz weitervererben können. Denn in diesem Fall verlinkt man nicht „LG”, sondern „LG Fernseher”.
Es ist aber davon auszugehen, dass Suchmaschinen diese Zusammenhänge erkennen und interpretieren können.

Verlinkung losgelöst von Filtern
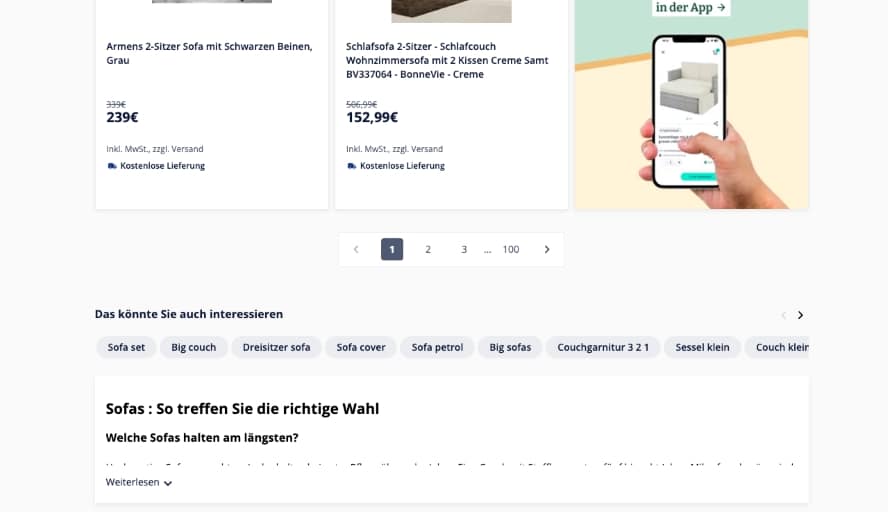
Manomano.de setzt bei der Verlinkung seiner Filterseiten auf ein Linkmodul unterhalb der Produktliste.
Bei manomano.de findet man keinen einzigen direkt verlinkten Filter. Stattdessen setzt man auf ein Linkmodul unterhalb der Produktliste.
Die besondere Leistung hierbei ist es, aus diesem Linkmodul ausschließlich zum Thema der Filterseite passende Seiten zu verlinken.
Auf diese Weise kann man die Filterindexierung maßgeblich vorantreiben und schafft es zugleich eine sehr hohe Güte in Bezug auf die eigene interne Verlinkung zu halten. Und gerade beim massiven Ausbau von Filterseiten unterstützt dieses Modul sehr gut das Wachstum des Shops.
Nicht zuletzt aufgrund dieser Filterindexierung konnte der Onlineshop in den letzten zwei Jahren seine Sichtbarkeit jeweils um dreistellige Prozentzahlen steigern.
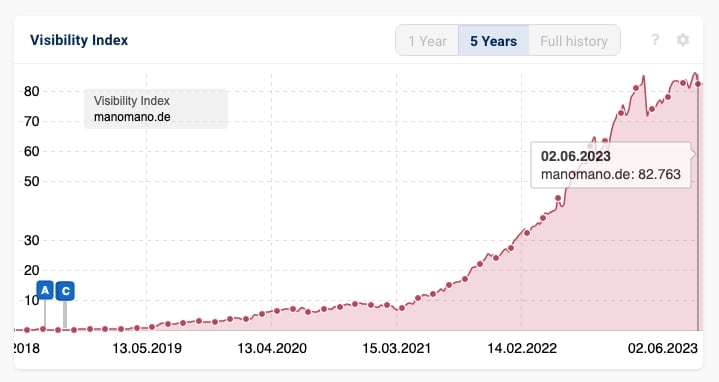
Einer der am schnellst wachsenden Onlineshops in DE ist manomano.de.
Onpage-Optimierung bei Filterindexierung
Die einfache Verlinkung der so entstehenden Filterseiten ist nicht ausreichend. Vielmehr gilt es, alle notwendigen Onpage-Maßnahmen auch bei diesem Seitentyp zu implementieren.
Darüber hinaus sollte jedes SEO-Inhouse-Team daran interessiert sein, diese Seiten auf URL-Ebene verändern zu können und das unabhängig von anderen Teams (zum Beispiel Produkt- und Entwicklungsteams). So kann man flexibel und schnell auf sich ändernde Rahmenbedingungen reagieren oder Lücken zum Wettbewerb schließen.
Basics der Onpage-Elemente für Filterseiten:
- Title und Description – Auch für Filterseiten sollten vor allem der Title und die Description individuell gepflegt sein, um darüber Relevanz zum Seitenthema zu signalisieren
- Überschriften (H1 bis Hn) – Elementar für alle Shopseiten, um Nutzern und Nutzerinnen klar zu signalisieren, auf welcher Seite sie sich befinden
- Content-Bereich – In manchen Fällen kann ein dezidierter Content-Bereich Sinn ergeben, um Conversion blockende Nutzerfragen zu beantworten oder die Relevanz zum Zielthema zu erhöhen
- Strukturierte Daten – Schemata, wie die für FAQs, sollten ebenfalls pflegbar oder direkt implementiert sein, um Snippet verbessernde Informationen gegenüber Suchmaschinen klar auszuzeichnen
- Indexierungs-Angaben – Die Möglichkeit, die Filterseiten einzeln per <meta name=”robots” content=”noindex,follow” /> aus dem Suchindex zu nehmen, sollte ebenfalls vorhanden sein. Gerade Filterseiten mit sehr spezifischen Themen und wenig Inventar neigen dazu, sehr schnell komplett ausverkauft zu sein
- Aufnahme in XML-Sitemap – Da bei sehr vielen Onlineshops Filterseiten technisch einen anderen Seitentyp darstellen, ist häufig nicht vorgesehen, sie in XML-Sitemaps aufzunehmen. Auch das sollte sichergestellt sein, um schnelle Indizierung zu forcieren und Monitoring-Prozesse zu unterstützen
TIPP: Eigene XML-Sitemap für Filterseiten
Gerade bei der neuen Filterindexierung bietet sich ein eigenes Segment “Filterseiten” auch bei den XML-Sitemaps an. Das ermöglicht zum einen ein einfacheres Monitoring des Indizierungsstatus und darüber hinaus eine ganz einfache Auswertung des durch diese Maßnahme hinzugewonnen Traffics. So macht man SEO-Erfolge auch gegenüber Dritten (zum Beispiel Management) von Anfang an sichtbar.
Technische SEO-Probleme mit Filtern identifizieren
Bei existierenden und für Suchmaschinen-Crawler erreichbaren Filter-URLs sollte zuerst auf Fehler untersucht werden.
Damit beugt man vor allem Nachteilen durch Linkkraftverschwendung, ineffizientes Crawling und Kannibalisierung durch Duplikate vor.
Die Wirkung von Fehlern potenziert sich gerade bei sehr großen Seiten ( > 100.000 URLs) und führt erfahrungsgemäß zu deutlichen Nachteilen im Ranking.
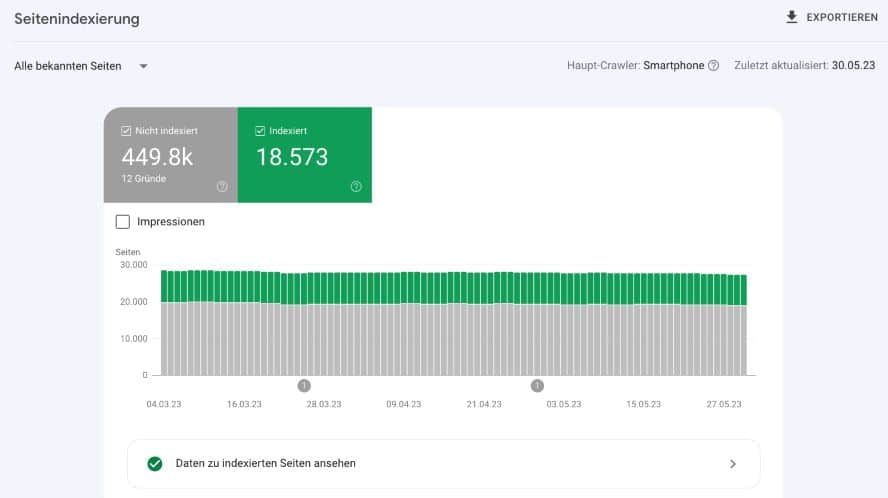
Wenn die GSC ein solches Missverhältnis von nicht indexierten zu indexierten Seiten zeigt, ist das ein deutliches Indiz für größere, technische Probleme.
Um Problemen mit Filterseiten begegnen zu können, müssen diese zunächst gefunden und analysiert werden. Im Folgenden wird erklärt, wie Symptome zunächst gefunden werden können.
1. Google Suchoperatoren
2. Logfiles
3. Google Search Console (GSC) – Abdeckungsbericht
4. Crawling
Google Suchoperatoren
Mit Hilfe von Suchoperatoren kann man relativ schnell herausfinden, ob Filterseiten im Index sind. Zumindest wenn diese dem gängigen Muster entsprechen und per an die URL angehängten Parameter zu identifizieren sind:
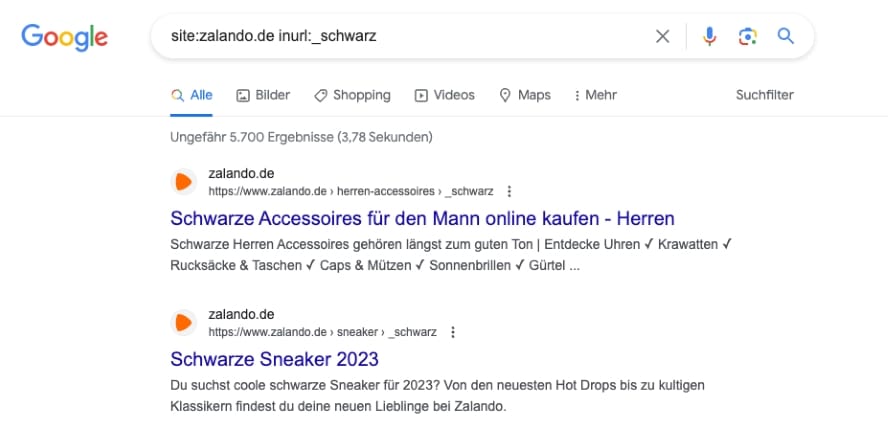
Alleine an indexierten Filtern zur Farbe „schwarz” besitzt zalando.de über 5.000.
Die Angabe der “ungefähren Ergebnisse” entspricht nicht 1 zu 1 der Realität, bietet aber ein erstes Indiz dafür, dass Filterseiten im Index gelandet sind.
Sollte diese Summe allerdings weit über den Erwartungen liegen, sollte man wahrscheinlich handeln und für die Problemursachen Lösungen finden.
Logfiles
Eine weitere Quelle, um Informationen zu Problemen mit der Filterindexierung zu bekommen, sind die eigenen Server-Logs. Logfiles bieten Informationen über Zugriffe auf einen Webserver bzw. eine Website.
Neben echten Nutzerdaten enthalten sie Zugriffe von Suchmaschinen-Bots. Damit sind sie die ideale Informationsquelle, um einen genauen Überblick zum Verhalten von Crawlern zu erlangen.
Mit Hilfe der Logfile-Analyse sollte man sich Antworten auf die folgenden Fragen suchen:
- Investieren Suchmaschinen einen relevanten Teil ihres Crawl-Budgets für das Crawling von gefilterten Seiten?
- Sind all diese Filterseiten indexierbar?
- Wie hoch ist der Anteil nicht indexierbarer URLs?
Auf diese Weise kann man quantifizieren, ob und wie groß ein Problem mit der Filterindexierung ist.
Dabei sollte man im Hinterkopf haben, dass diese URLs nur dann gecrawlt werden, wenn sie durch starke Signale (z.B. interne Links, XML-Sitemaps oder externe Verlinkungen) Suchmaschinen gegenüber „bekannt gemacht” wurden.
Ist das regelmäßig investierte Crawl-Budget für irrelevante Filterseiten hoch, gilt es dieses durch die hier beschriebenen Maßnahmen auf sinnvollere URLs zu konsolidieren.
Google Search Console (GSC) – Abdeckungsbericht
Der Abdeckungsbericht in der Google Search Console ist eine gute, erste Anlaufstelle für die Identifikation von Problemen. Zum Start reicht ein einfacher Blick in die Übersicht, um zu erkennen, wie das Verhältnis von indexierten zu nicht indexierten URLs ist.
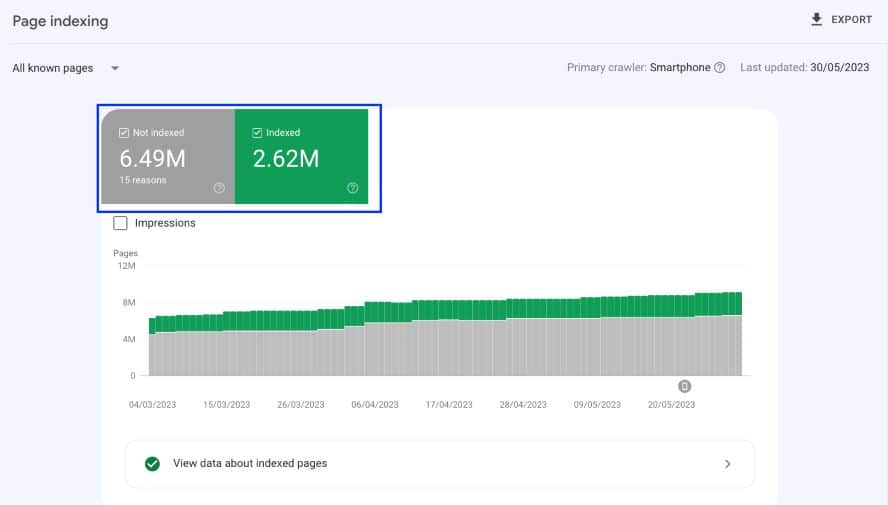
Der Abdeckungsbericht der Google Search Console ist ein guter Start, um Probleme mit der Filterindexierung zu identifizieren.
Im obigen Beispiel herrscht ein eher unausgewogenes Verhältnis, so dass der Verdacht naheliegend ist, dass auch Filterseiten darunter fallen.
Deshalb bietet es sich an, auf die etwas detaillierteren Berichte unter “Warum Seiten nicht indexiert werden” zu schauen.
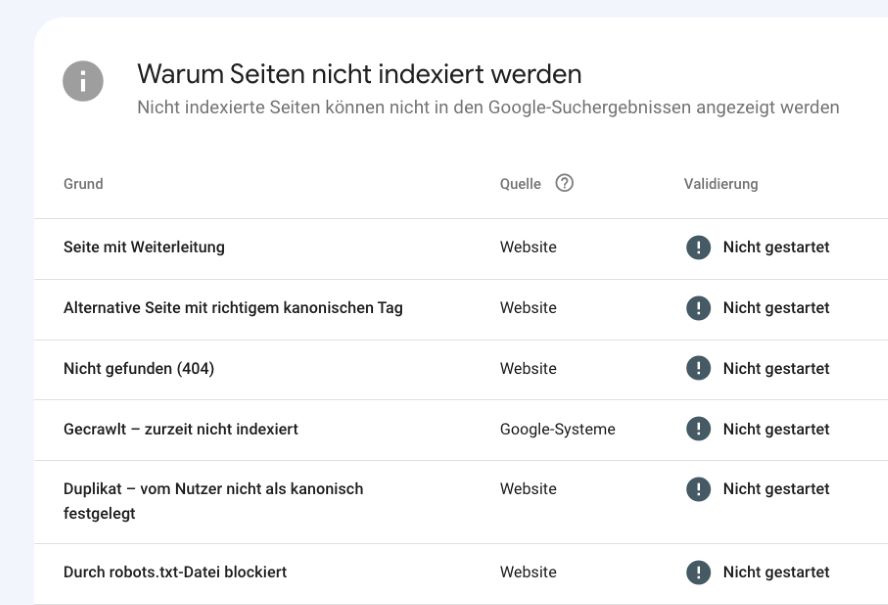
Liste unterschiedlicher Fehlerberichte der Google Search Console.
Grundsätzlich geht es in diesem Schritt darum herauszufinden, ob Filterseiten zu einem großen Teil dort in diesen Berichten auftauchen.
Beispiele
- Durch “noindex”-Tag ausgeschlossen: Sollten irrelevante Filterseiten bereits von der Indizierung ausgeschlossen sein, ist das ein Indiz dafür, dass sie weiterhin verlinkt sind. Man verschwendet also Linkkraft und Crawl-Budget an Seiten, die nicht indexiert werden sollen
- Alternative Seite mit richtigem kanonischem Tag: Die Webseite nutzt den Canonical-Tag, um unerwünschte Filterseiten aus dem Index zu halten. Auch dies ist ein Indiz dafür, dass diese Seiten weiterhin durch interne Verlinkung für Crawler zugänglich sind und stellen potenziell eine Verschwendung von wertvollen Ressourcen dar
- Gecrawlt – zurzeit nicht indexiert: Ganz allgemein kann man hier davon ausgehen, dass die darin enthaltenen URLs die Mindestanforderungen an Qualität nicht erfüllen. Gerade gefilterte URLs weisen oft diese Probleme auf, weil sie ein spezifisches Abbild einer größeren Kategorieseite darstellen und dadurch dieser sehr ähnlich sind. Fehlende Einzigartigkeit ist also das Problem.
Crawling
Natürlich bietet es sich an, mit einem der vielen Crawling-Tools (z.B. ScreamingFrog, Audisto, SISTRIX-Optimizer oder Tool-Suits wie ahrefs und SEMrush) die eigene Seite zu analysieren.
Alle vorangegangenen Methoden führen zwar zum Ziel, bieten aber auf den ersten Blick keine Übersicht über die Schwere von Problemen bei der Filterindexierung.
Mit Hilfe von Crawlern, vor allem der SAAS-Tools, kann man Folgendes schnell sehen:
- Verteilung des Indexierungsverhältnisses von Filterseiten: Je nach Verteilung besteht entweder das Problem, dass zu wenig oder viel zu viele Filterseiten indexiert werden.
- Summe der auf irrelevante Filterseiten verlinkenden, internen Links: Werden irrelevante (kein organisches Suchvolumen für Thema der URL) Seiten intern sehr oft verlinkt, werden Crawling- und Linkressourcen verschwendet.
Die Interpretation der Crawling-Ergebnisse ist also abhängig vom Erwartungswert. Wenn nur eine gezielte Filterindexierung erfolgen soll, ist eine viel zu große Anzahl indexierte Filter ein Hinweis darauf, dass das Index-Management überarbeitet werden muss.
Findet der Crawler nur ganz wenige indexierbare Filter-URLs im gleichen Szenario, scheinen diese nicht zugänglich oder indexierbar zu sein.
Von diesen Erkenntnissen hängen die unterschiedlichen Lösungen dann ab.

Probleme der Filterindexierung lösen
Es existieren unterschiedliche Varianten, um Problemen bei der Filterindexierung zu begegnen. Grundsätzlich lässt sich darüber hinaus aber festhalten:
- Crawler entdecken URL-(Muster) hauptsächlich durch Folgen von internen Links
- Darüber hinaus existieren Signale, die die Relevanz von Filterseiten zusätzlich gegenüber Suchmaschinen herausstellen: z.B. Backlinks oder Einträge in XML-Sitemaps
Um Verschwendungen im Crawling und bei der internen Verlinkung von Filterseiten zu verhindern, ist es erforderlich, die Signale zu irrelevanten Seiten weitestgehend zu entfernen.
Auch wenn alle folgenden Varianten zur Behebung unerwünschter Filterindexierung existieren, sollte der individuelle Kontext der eigenen Ausgangssituation bedacht werden.
Grundsätzlich kann man aber diesen Schritten folgen:
- Zunächst irrelevante URLs zu reduzieren (z.B. durch Löschung, „noindex”)
- Fehlende und relevante Facetten hinzufügen (z.B. basierend auf einer Keywordrecherche)
- Bestehende Seiten verbessern (z.B. Snippets individualisieren, einzigartige Inhalte in SEO-Elementen integrieren)
1. Ausschluss via robots.txt
2. Canonical-Tag
3. „noindex“
4. Links entfernen und maskieren
5. Übersicht zu Methoden der Filterindexierung
Ausschluss via robots.txt
Diese Lösung sollte nur im Ausnahmefall und bei „Problemen mit Crawl-Budget” eingesetzt werden. Kurzfristig gelingt es hiermit, das Crawling auf irrelevante Seitenbereiche zu unterbinden.
Aber Achtung: Die Filterindexierung kann man auf diese Weise nicht rückgängig machen. Durch die Einträge in der robots.txt wird nur das Crawling von Suchmaschinen-Bots gesteuert. Die Steuerung der Indexierung einer URL kann durch diese Methode nicht erreicht werden
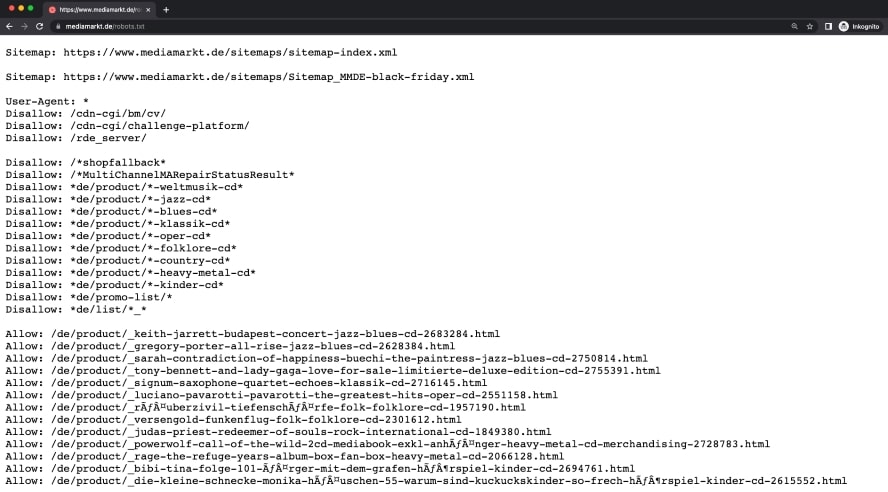
Robots.txt auf mediamarkt.de
Praktisches Beispiel (fiktiv)
Wenn zooplus.de keine mit einer Marke gefilterten URLs crawlen lassen will, müsste man mit einem sogenannten “Disallow” das Crawling für eben dieses URL-Muster verbieten.
Beispiel URL: https://www.zooplus.de/shop/hunde/hundefutter_trockenfutter/getreidefrei_trockenfutter?filters=brand%3DGreenwoods
User-agent: *
Disallow: *filters=brand=*
Nachteile
Durch den Einsatz können einmal indexierte, irrelevante Filter-URLs nicht aus dem Suchindex entfernt werden. Lediglich eine verbesserte Nutzung von Crawling-Ressourcen wird erreicht.
Darüber hinaus:
- Keine eindeutigen URL-Muster: Ohne klare Muster wird es sehr schwer generelle Regeln zu definieren.
- Zu viele individuelle Regeln: Sehr komplex wird es, sobald Regeln dazu führen, dass unerwünschte Seitenbereiche ausgeschlossen werden. In diesem Fall könnte man dann wieder spezifische Seitenbereiche zulassen. Insgesamt aber ein sehr komplexes Unterfangen.
Grundsätzlich sollte das Prinzip gelten, so wenige Regeln wie möglich in der robots.txt zu hinterlegen. Diese bekämpfen nur Symptome einer zu verbessernden Informationsarchitektur.
Canonical-Tag
Eine weitere Möglichkeit, die Filterindexierung zu steuern, ist der Canonical-Tag.
Das Canonical-Tag vereinigt die Ranking-Signale (z.B. interne und externe Links) von identischen URLs und führt diese auf einer einzigen sogenannten „kanonischen URL“ zusammen.
Als Konsequenz daraus werden die Duplikate der kanonischen URL weniger häufig gecrawlt und die kanonische URL in den Suchergebnissen angezeigt.
Mutmaßlich profitiert die kanonische URL von der Konsolidierung der Ranking-Signale aller Duplikats-Varianten.
Implementierungsbeispiel:
Für https://www.domain.de/category/ existiert eine irrelevante Filterseite https://www.domain.de/category/?=filter_value.html
Canonical der Filterseite:
<a rel=”canonical” href=”https://www.domain.de/category/”/>
In der Regel ist der Vorteil des Canonicals, dass es unkompliziert implementierbar ist und sich so der Umsetzungsaufwand stark in Grenzen hält. Darüber hinaus ist die Zusammenführung von Ranking-Signalen auf einer für SEO relevanten URL gewährleistet. Aus SEO-Sicht geht man davon aus, dass dies sogar einen positiven Einfluss auf das Ranking dieser URL hat.
Allerdings liefert Google in seiner Dokumentation selber die größten Nachteile, wenn man bei der Filterindexierung auf das Canonical setzt.
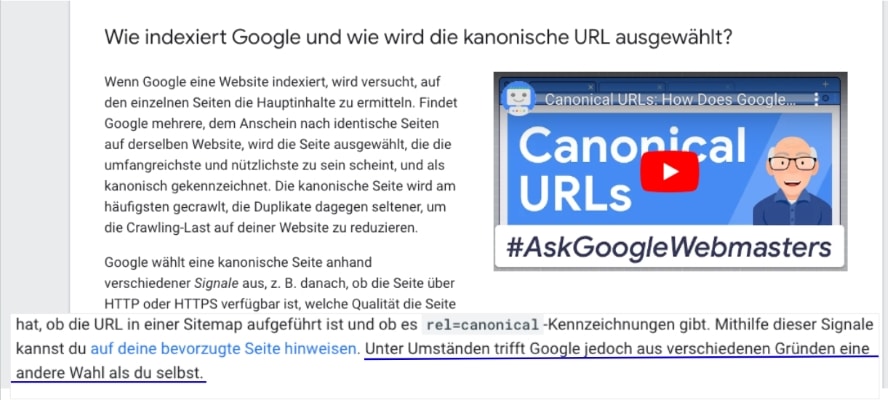
Laut eigener Dokumentation sagt Google selber, dass sie aus nicht näher genannten Gründen jederzeit entscheiden können, den Canonical-Tag zu ignorieren.
Und auch zum Wirkungsgrad erklärt Google eindeutig:
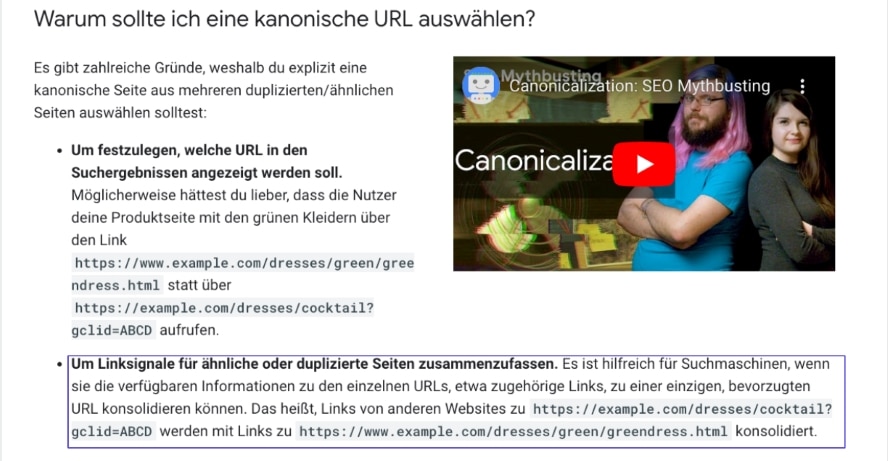
Eines der „bestätigten” Ziele beim Einsatz des Canonical ist die Konsolidierung aller positiven (Ranking-) Signale auf einer einzigen URL
Weitere Informationen zur URL-Kanonisierung finden sich in Googles-Dokumentation (Quelle: google.com)
Es ist also keine Methode, die in jedem Fall zum beschriebenen Ergebnis führt. Gerade bei komplexeren Webseitenstrukturen erkennt man häufig, dass Canonical-Anweisungen ignoriert und URLs dennoch in der Suche angezeigt werden.
Alleine dieser Umstand macht deutlich, dass auch das Canonical-Tag keine langfristige Lösung für die Filterindexierung darstellen kann.
„noindex“
Die einzig sichere Maßnahme, um alle irrelevanten Filterseiten aus dem Suchindex zu entfernen, ist das Robots-Meta-Tag mit dem Wert “noindex”. (Quelle: developers.google.com)
<meta name=”robots” content=”noindex,follow”>
Dieses Meta-Tag müsste im <head> der betroffenen Filterseiten implementiert werden oder falls bereits vorhanden von “index” auf “noindex” geändert werden.
Links entfernen und maskieren
Die mit Abstand nachhaltigste Methode ist es, die internen Verlinkungen auf irrelevante Filterseiten komplett zu entfernen. Dieses Vorgehen bezeichnet man als „Maskierung”.
Indem man die interne Verlinkung für Suchmaschinen-Crawler versteckt, werden diese nicht gecrawlt. Darüber hinaus entfällt die Vererbung von Linkkraft. Automatisch verbessert man also den erhaltenen Pagerank aller anderen erreichbaren Seiten.
Der Einsatz von Methoden der Linkmaskierung macht nur in zwei Szenarien Sinn:
- Bevor Suchmaschinen die Filter-URLs kennen: Idealerweise zum Zeitpunkt eines (Re-)Launches. Da Crawlern kein Pfad zu Filterseiten gezeigt wird, sind diese auch nie erreichbar und werden demnach nicht indexiert.
- Nach De-Indexierung aller Filterseiten: Die Methode wird mit dem “noindex” kombiniert. Sobald daraufhin alle URLs aus dem Index verschwunden sind, maskiert man die internen Links zu diesen URLs.
Zu bedenken ist, dass in jedem Fall sämtliche Verlinkungen und Signale zu diesen URLs aus dem Onlineshop verschwinden (z.B. XML-Sitemaps, Recommendation-Engines, Links aus redaktionellen Beiträgen).
Varianten der Linkmaskierung
Die detaillierte Erklärung von Linkmaskierung innerhalb dieses Artikels würde zu weit führen. Glücklicherweise gibt es die folgenden, wertvollen Ressourcen, die einen tiefen Einblick in unterschiedliche Lösungsvarianten geben:
- Linkmaskierung durch das Post-Redirect-Get-Pattern (PRG-Pattern)
- Effektive Linkmaskierung in der SEO mit onclick-Events (Rene Dhemant) (Quelle: rene.fyi)
Übersicht zu Methoden der Filterindexierung
Alle vorgestellten Varianten bieten ihre eigenen, charakteristischen Vor- und Nachteile in Bezug auf die Beeinflussung der beiden Faktoren “Crawling” und “Indexierung”:
| Methode | Crawling | Indexierung | Einordnung |
| robots.txt | ✔ | ✖ | verhindert lediglich das Crawling der Filterseiten. Indexierung kann dennoch erfolgen. |
| canonical | ✖ | ✖ | Lediglich eine Empfehlung an Suchmaschinen, die diese ignorieren können. |
| noindex | ✖ | ✔ | Kann als kurzfristiger Hebel / “Quick-Fix” eingesetzt werden. |
| Links maskieren / entfernen | ✔ | ✔ | Wirkt sich sowohl positiv auf das Crawling, als auch die indexierung aus – Nicht verlinkte Filter-URLs werden nicht (mehr) gecrawlt + indexiert (inkl. Verbesserung interne Verlinkung). |
Die komplexeste Variante (Link-Maskierung) ist auch mutmaßlich die technisch herausforderndste in Bezug auf den Umsetzungsaufwand.
In der Praxis empfiehlt sich daher diese Maßnahmenreihenfolge, absteigend nach Güte der Lösung:
- Linkmaskierung / Entfernung von Links: Beste Lösung, um Crawling und Indexierung irrelevanter Filterseiten zu verhindern. Gleichzeitig positiver Effekt auf die Verteilung interner Linkkraft
- Einsatz des “noindex”: Sollte relativ einfach umsetzbar sein und hat vor allem kurzfristig einen Effekt, ganz ähnlich einer “Panda Diät”. Es bleibt die Unsicherheit des “Longterm noindex”(get:traction)
- Canonical-Tag: Auf Canonicals zur Steuerung der Indizierung angewiesen zu sein, ist nicht zu empfehlen. Dennoch, wenn keine andere Lösung implementiert werden kann, bleibt nur diese Maßnahme.
- Robots.txt: Nur wenn ein Shop tatsächlich und nachweislich massive Crawling-Probleme besitzt, zu empfehlen. Ist aber nicht geeignet, um die Filterindexierung zu steuern und damit gänzlich ungeeignet für diesen Kontext.

Zusammenfassung
Die Filterindexierung ist eines der zentralen Themen in der SEO-Strategie. Bei vielen Onlineshops bietet sie relevantes Wachstumspotenzial oder muss grundsätzlich zielgerichtet überarbeitet werden.
Dabei ist darauf zu achten, in welcher individuellen Situation sich ein Shop befindet. Diese Standortbestimmung ist wichtig, um die richtigen, technischen Maßnahmen ableiten zu können.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





