
Wie Danny Sullivan kürzlich bestätigte, wurde der Link zum Google Cache auf der Suchergebnisseite (SERP) Ende Januar entfernt (Quelle: twitter.com). Welche Gründe hinter der Abschaltung stecken und wie du weiterhin auf die gecachte Version von Webseiten zugreifen kannst, findest du im nachfolgenden Artikel.
Was ist der Google Cache?
Google speichert beim Crawlen einer Webseite eine Kopie dieser auf einem hauseigenen Server. Die Datei wird auch als Schnappschuss bezeichnet. Diese Funktion nennt sich Google Cache.
Genau genommen speichert Google keine einzelne Kopie, sondern mehrere Dateien. Meist wird eine Raw- und eine gerenderte Version abgespeichert.
Warum speichert Google beim Crawlen einer Webseite eine Kopie?
Google kann durch das Speichern der Webseite den Zugriff auf diese sicherstellen, auch wenn die Live-Version einer Webseite aufgrund von Lade- oder Serverproblemen zurzeit nicht erreichbar ist. Spielt Google den zwischengespeicherten Schnappschuss aus, erscheint am oberen Rand ein entsprechender Hinweis.
Wie konnte ich auf die im Google Cache gespeicherte Version über die SERP zugreifen?
Informationen zu diesem Ergebnis
Google bietet in den Suchergebnissen die Möglichkeit, weitere Informationen über die Webseite zu erhalten. Über einen Klick auf die drei Punkte neben dem Webseiten Pfad innerhalb des Snippets, öffnet sich das Fenster „Informationen zu diesem Ergebnis“. Über die Schaltfläche „Im Cache“ konnte die von Google gecachte Version der Webseite angezeigt werden.
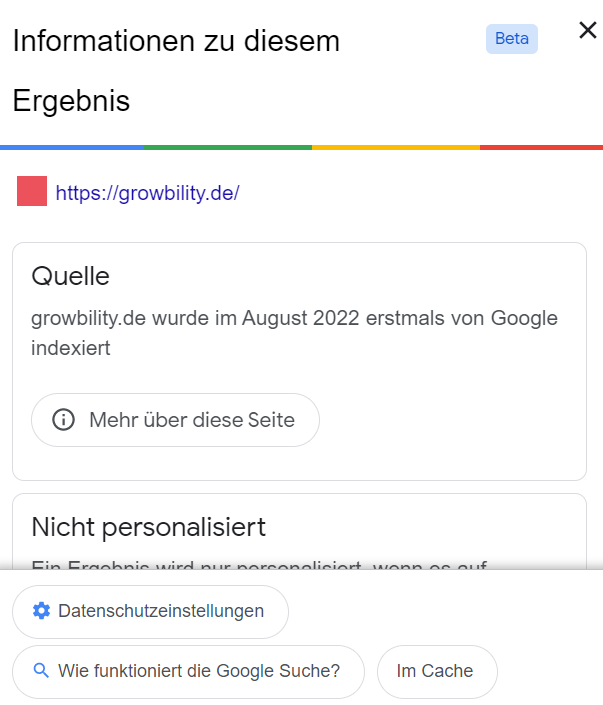
Über das Fenster „Informationen zu diesem Ergebnis“ lässt sich die zwischengespeicherte Version einer Webseite öffnen
Warum hat Google den Button entfernt?
Google plant, das Caching komplett einzustellen. Wie Danny Sullivan auf Twitter bekannt gab, wird die zwischengespeicherte Kopie der Webseite aufgrund der zunehmenden Verbreitung des Internets ganz einfach nicht mehr benötigt. Derzeit kann mit Hilfe des Google Operators cache noch auf die zuletzt gespeichert Version zugegriffen werden, mittelfristig wird es jedoch kein Caching mehr geben. Unter Umständen wird ein Link auf die Waybackmachine (siehe unten) im Fenster „Informationen zu diesem Ergebnis“ integriert. Dies sei jedoch noch nicht entschieden.
Wie kann ich jetzt auf die von Google gecachte Version meiner Webseite zugreifen?
Über den Googe Operator cache kannst du aktuell noch auf die zuletzt von Google gespeicherte Datei einer Webseite zugreifen. Durch Aufruf einer URL mit vorangestelltem Google Operator cache, wird die zuletzt gespeicherte Version aufgerufen. Dazu wird der Operator gefolgt von der URL der Webseite in das Suchfeld bei Google eingegeben.
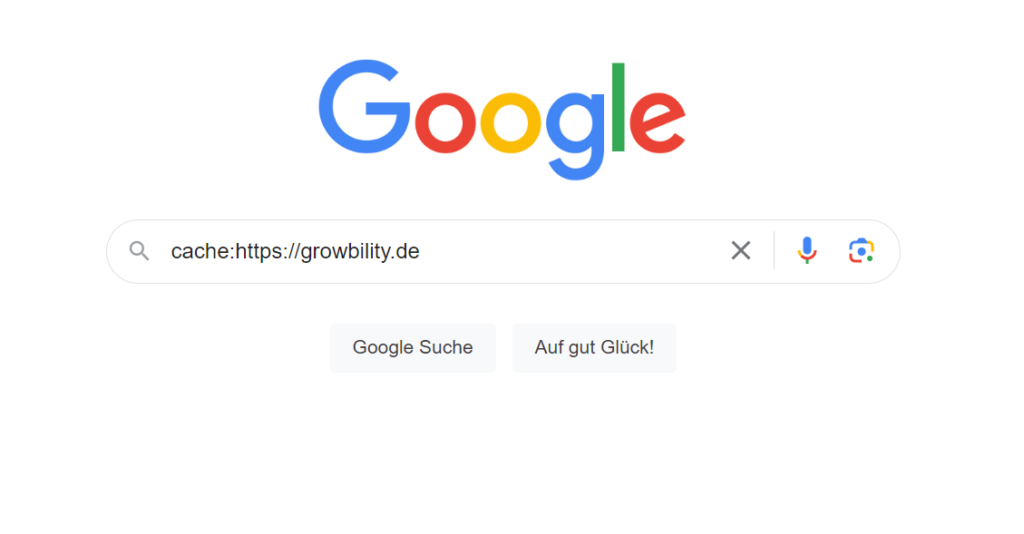
Der Operator cache öffnet die von Google zwischengespeicherte Version einer Website.
Hat der Google Cache Einfluss auf mein Ranking?
Der Google Cache hat kein Einfluss auf das Ranking einer Webseite.
Wie kann ich auf ältere Versionen meiner Webseite zugreifen?
Google ermöglicht nur noch den Zugriff auf die aktuell gespeicherte Version einer Webseite. Die Wayback Machine dagegen ist eine Art Archiv von Webseiten. Im März 2023 verfügte die Wayback Machine über mehr als 800 Billionen gespeicherte Webseiten (Quelle: en.wikipedia.org). Über die URL https://archive.org/web/ kannst du also nahezu von allen Webseiten der Welt zwischengespeicherte Versionen abrufen.
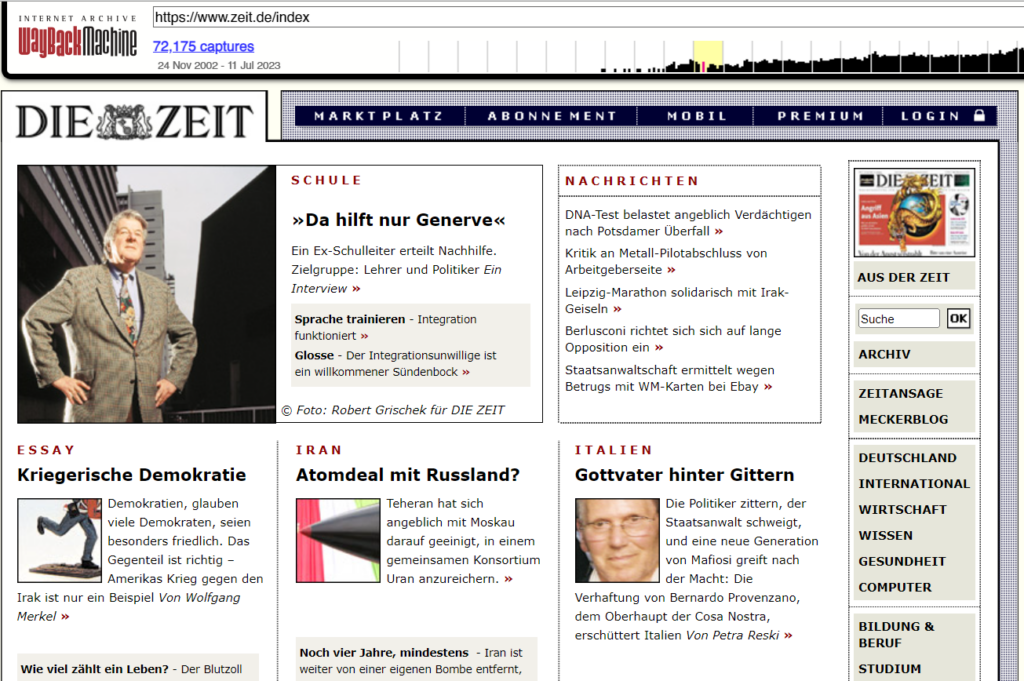
Die Startseite der Zeit am 23.4.2006, (Quelle: web.archive.org)
Viele SEO’s nutzten den Zugriff auf die gecachte Version für eine Analyse des Crawlings einer Webseite. Danny Sullivan verweist dafür auf das Inspection Tool der Google Search Console.
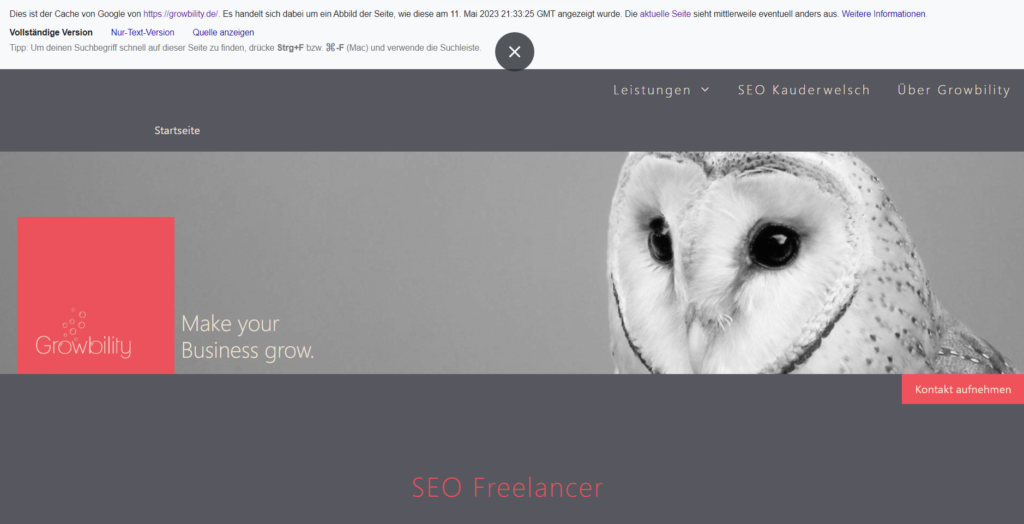
Die Webseite growbilty.de im Google Cache
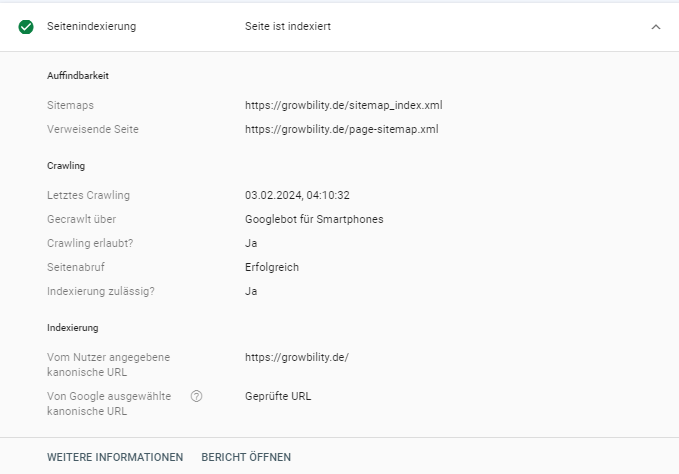
Ergebnis der Überprüfung der URL https://grownbilit.de mit dem Inspection Tool der Google Search Console
Crawlingzeitpunkt
Google gibt an, wann dieses Abbild der Webseite gespeichert wurde. Das ist gleichzeitig der Zeitpunkt des letzten Crawlens. SEO’s nutzten diese Funktion beispielsweise, um Herauszufinden ob eine Aktualisierung auf der Webseite bereits indexiert ist. Der Aktualisierungszyklus der Webseite im Google Cache gibt Aufschluss darüber, wie oft diese geändert wird. Findet der Google Crawler regelmäßig neuen Content, so wird er diese in kurzen Abständen crawlen. Bei Webseiten mit wenig Content-Updates, stellt Google den Crawlingzyklus auf größere Abstände.
Wie im obigen Bild zu sehen ist, erhält man diese Information ebenso bei der Überprüfung einer URL über das Inspection Tool der Google Search Console. Allerdings können über die Google Search Console nur URLs der eigenen Webseite überprüft werden. Ein Zugriff auf Webseiten von Wettbewerbern ist nicht möglich. Hierfür konnte über die gecachte Version beobachtet werden, ob Wettbewerber regelmäßig Aktualisierungen publizieren, ohne dafür den Inhalt abzugleichen.
Crawlability
Der Aufruf der von Google gecachten Webseite wurde auch gerne als Test der Crawlability von Webseiten genutzt. Befindet sich auf der gespeicherten Version der komplette Inhalt, so konnte der Google Crawler diesen lesen. Dies ist wichtig, denn nur wenn Suchmaschinencrawler den kompletten Inhalt lesen können, wird dieser in den Index aufgenommen. Allerdings gab Google schon länger an, dass fehlende Inhalte auf der gespeicherten Version kein eindeutiger Hinweis auf Probleme der Crawlabilty sind. Vielmehr sollte das Java.Script-Rendering mit Hilfe der Google Search Console getestet werden.
Das Java-Script-Rendering kannst du über die Google Search Console testen:
- Google Search Console öffnen
- URL über das URL-Prüftool testen
- Bericht „Nutzerfreundlichkeit auf Mobilgeräten“ öffnen
- Hier kannst du den von Google erfassten HTML Code einsehen und so überprüfen, ob Inhalte wie z. B. die Links in der Navigation erfasst werden.
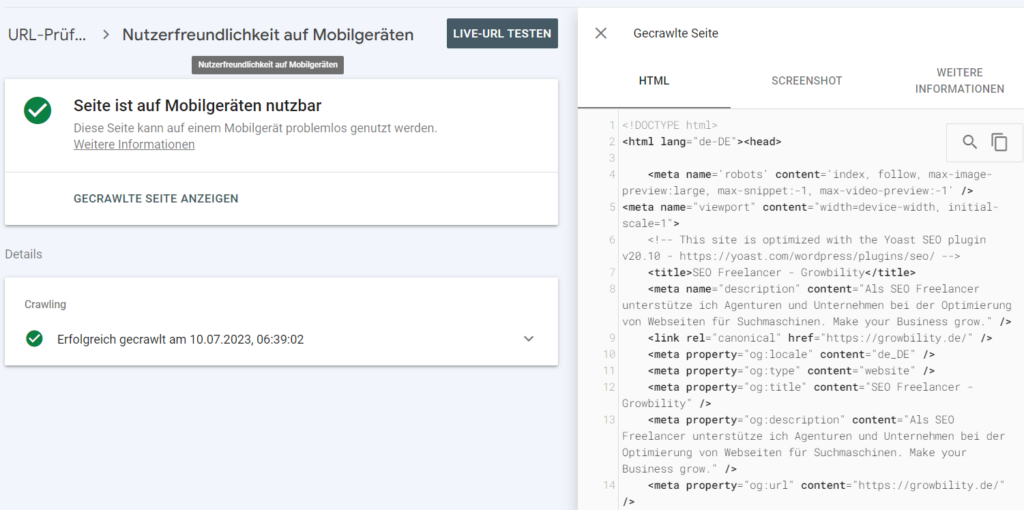
Das Java Script Rendering kann in der Google Search Console überprüft werden
Was passiert mit dem Meta-Tag noarchive?
Webseiten mit häufigen Aktualisierungen schalten die Caching Funktion häufig mit Hilfe des Meta-Tags noarchive ab. Dazu genügt das Hinzufügen des folgenden Meta-Tags im Header im Quellcode der Webseite:
<meta name=”robots” content=”noarchive”>
Vor allem Newsseiten greifen auf diese Möglichkeit zurück, da die zwischengespeicherte Version veraltete Inhalte enthalten kann. Dieser HTML Ausschnitt ist von der Webseite der ZEIT:
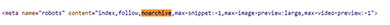
Das Meta-Tag „noarchiv“ verhindert, dass Suchmaschinen eine gespeicherte Datei der Webseite auf ihren Servern ablegen (Quelle: zeit.de)
Die Indexierung der Seite wird dadurch nicht verhindert. Die URL wird in den Suchindex aufgenommen. Soll eine URL nicht von Suchmaschinen indexiert werden, kommt das Meta-Tag nonidex im Quellcode der Seite zum Einsatz:
<meta name=”robots” content=”noindex”>
Stößt ein Suchmaschinenbot beim Crawlen einer Webseite im Quellcode auf dieses Tag, wird der Inhalt gecrawlt, jedoch nicht indexiert. Für Seiten, die nicht gecrawlt werden sollen, kann ein entsprechender Eintrag in der robots.txt eingesetzt werden. Der Befehl „Disallow:“ gefolgt von einer URL oder auch einem ganzen Verzeichnis verbietet Suchmaschinen das Crawlen dieser.
Danny Sullivan antwortet bei der Rückfrage, was nun mit dem Meta-Tag noarchive geschehen soll, dass es nicht aus dem HTML-Code von Webseiten entfernt werden muss. Andere Crawler werden diese Information weiterhin nutzen.
Fazit
Noch kann mit Hilfe des Google Operators cache auf die zuletzt gespeicherte Version einer Webseite zugegriffen werden. Mittelfristig wird jedoch kein Caching mehr erfolgen. Für uns SEO’s gibt es jedoch weiterhin Möglichkeiten und Wege, auf Informationen bzgl. des Crawlings zuzugreifen. Die Waybackmachine enthält viele Dateiversionen einer Webseite und kann so weiterhin als Archiv genutzt werden.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





