
Viele SEOs orientieren sich bei der Erstellung von eigenen Inhalten mehr oder weniger stark an den Top-10 Suchergebnissen des gewählten Keywords. Schließlich hat Google diese Inhalte ja bereits „für gut befunden“.
Anfang Oktober 2021 hat John Müller auf Twitter nochmals klargestellt, dass Unique Content nicht durch das Umformulieren von bereits bestehenden Inhalten erreicht wird. Es gehe nicht um individuelle Wortkombination.

Durch die Nutzung von Synonymen und kleinen textlichen Änderungen würde nichts Besonderes entstehen. Um das Vertrauen der Nutzer gewinnen zu können, solle man etwas Neues schaffen, so Müller.
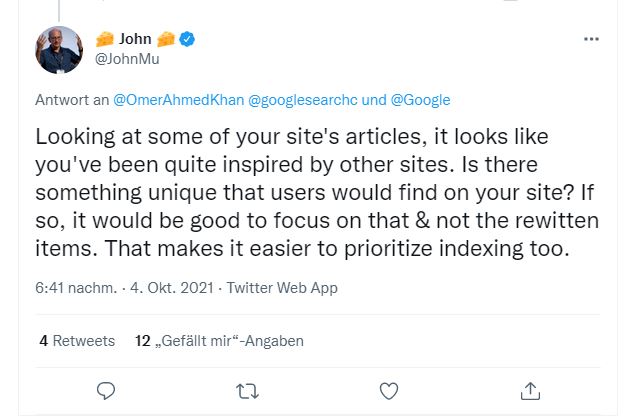
Twitter-Posts von John Müller im Oktober 2021 zu Unique Content und dem Umformulieren von bestehenden Inhalten.
In Anbetracht dessen lohnt es sich einen Blick auf ein Google Patent aus dem April 2020 zu werfen.
Patent zur Bewertung des Erkenntnisgewinns von Suchergebnissen
Google hat erkannt, dass Nutzer wenig Interesse daran haben, sich ein zweites Ergebnis anzusehen, das dem ersten stark ähnelt. Daher haben sie unter dem Titel „Contextual Estimation of Link Information Gain“ ein Patent eingereicht, das genau dieses Problem lösen soll.
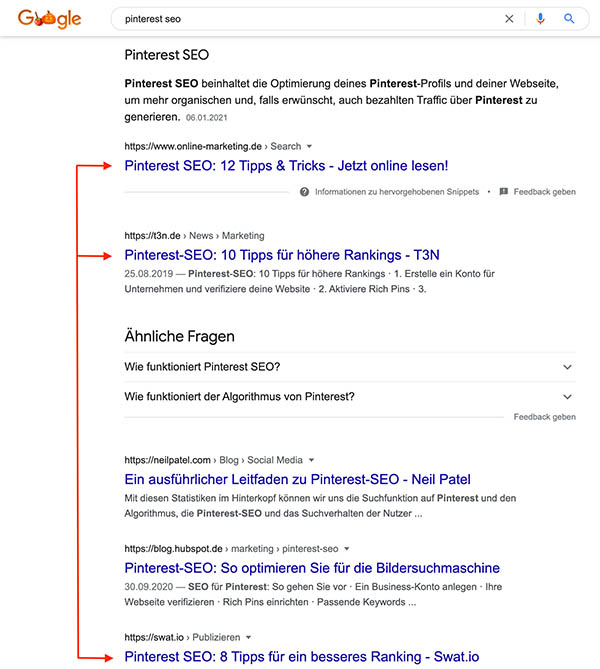
Wie viel Erkenntnisgewinn liefern Suchergebnisse für die Nutzer, wenn sich schon die Titel stark ähneln?
Im Kern geht es darum, dass für jedes relevante Ergebnis ein sogenannter „Information Gain Score“ berechnet werden soll. Dieser beschreibt, wie viel Erkenntnisgewinn das Ergebnis für den Nutzer generiert, der bereits andere Suchergebnisse zu diesem Thema angesehen hat. Im Patent heißt es, dass relevante Ergebnisse zumindest teilweise basierend auf dem jeweiligen „Information Gain Score“ gerankt werden können.
Das bedeutet, Inhalte mit einem höheren Erkenntnisgewinn könnten folglich bessere Rankingpositionen erzielen als Seiten, die dem Nutzer wenig einzigartige Informationen präsentieren.
Wie wird der Information Gain Score berechnet?
In seinem Blog „SEO by the Sea“ analysiert Bill Slawski die SEO-Auswirkungen verschiedener Google Patente.
In einem ausführlichen Beitrag beschreibt er die Funktionsweise des Patents wie folgt:
Zuerst werden verschiedene Daten über die relevanten Suchergebnisse gesammelt, die Rückschlüsse auf den Erkenntnisgewinn der Dokumente zulassen. So werden vor allem der Inhalt und Passagen, die mit hoher Wahrscheinlichkeit aus anderen Ergebnissen extrahiert sind, analysiert. Zusätzlich wird eine semantische Repräsentation der Ergebnisse erstellt.
All diese Daten werden anschließend in ein trainiertes Machine Learning Modell gegeben. Dabei wird der wahrscheinliche Erkenntnisgewinn von noch nicht angesehenen („neuen“) Suchergebnissen im Verhältnis zu den zuvor bereits angesehenen Dokumenten errechnet.
Vereinfacht dargestellt verläuft der Prozess wie folgt:
- Identifikation des ersten Sets an Dokumenten, das dem Nutzer angezeigt werden soll.
- Identifikation der Dokumente aus dem ersten Set, die ein gemeinsames Thema behandeln.
- Der Nutzer sucht nach einem bestimmten Thema und eine oder mehrere Seiten, die das eingegebene Keyword bedienen, werden ausgespielt.
- Für jede Seite aus dem zweiten Set wird ein „Information Gain Score“ berechnet, der den Erkenntnisgewinn der Seite im Verhältnis zu den zuvor ausgespielten Dokumenten berechnet.
- Basierend auf dem „Information Gain Score“ werden dem Nutzer ein oder mehrere „neue“ Seiten präsentiert. Die übrigen Dokumente werden gemäß ihres Erkenntnisgewinns sortiert.
- Wenn der Nutzer weitere Inhalte ansieht, werden die verbliebenen Dokumente basierend auf dem aktualisierten „Information Gain Score“ neu bewertet.
Beeinflusst der Information Gain Score das Ranking?
Nur weil Google ein Patent einreicht, muss das noch lange nicht bedeuten, dass die Technologie bereits aktiv in der Suchmaschine genutzt wird. Sowohl die generelle Entwicklung seit dem Hummingbird-Update im Jahr 2013 als auch die aktuellen Tweets von John Müller sprechen aber dafür, dass das Umschreiben von Inhalten auf Dauer kein Erfolgsrezept mehr ist.
Einige englischsprachige SEOs, wie Steve Toth oder Koray Tuğberk GÜBÜR haben das Patent rundum den Information Gain Score bereits aufgegriffen und geben Empfehlungen, wie Du den Erkenntnisgewinn Deiner Inhalte steigern kannst.
In einem aktuellen LinkedIn-Post erklärt Toth, wie er die Rankingpositionen für zwei seiner Artikel erheblich verbessern konnte. Hierfür notierte er die Überschriften (H1-H3) der Top-Suchergebnisse des bestimmten Keywords. Alle Überschriften, die er in seinen Inhalten noch nicht bediente, hat er umformuliert und dazu einen Absatz von etwa 200 Wörtern geschrieben.
Anschließend hat er diese Absätze mit eigenen Inhalten (Information Gain) aufgewertet. Laut Toth habe dies zu erheblichen Steigerungen der Klickzahlen der Artikel geführt.
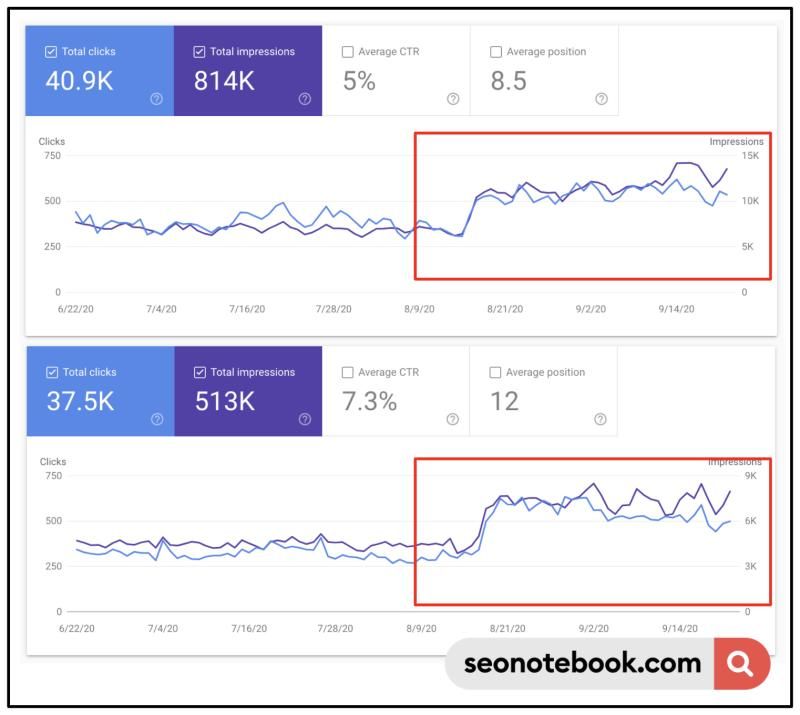
Steve Toth konnte die Rankingpositionen seiner Inhalte erheblich steigern, durch das Zusammenfassen von bestehenden Inhalten und die gezielte Anreicherung dieser Inhalte mit einzigartigen Informationen. (Bild: linkedin.com)
Selbstverständlich weiß auch ich nicht, ob und inwieweit Google die im Patent beschriebene Technologie bereits nutzt. Allerdings habe ich hierzu eine interessante Beobachtung gemacht. Einer meiner ersten Blogartikel behandelt das Thema „Wie funktioniert eine Suchmaschine?“. Dieser Artikel unterscheidet sich in Inhalt und Länge stark von den zuvor rankenden Suchergebnissen, da er größtenteils aus Informationen aus Fachbüchern und anderen Quellen besteht.
Die meisten Ergebnisse zu diesem Thema beschreiben die Funktionsweise einer Suchmaschine für den Ottonormalverbraucher und gehen dabei wenig auf die technischen Hintergründe ein. Dieser Artikel hingegen probiert die öffentlich bekannten, technischen Details der Funktionsweise einer Suchmaschine zu erklären. So unterscheidet er sich in Inhalt und Länge stark von den anderen relevanten Dokumenten.
Die durchschnittliche Domain-Autorität der organischen Suchergebnisse auf der ersten Seite für das Keyword „Wie funktioniert eine Suchmaschine?“ (monatliches Suchvolumen: 210) liegt bei einem Wert von 29. Der von mir betreute Blog kommt auf eine Autorität von 8 (Stand: 21.10.2021).
Außerdem habe ich bisher nur geringfügige technische SEO-Optimierungen vorgenommen. Dennoch rankt dieser Artikel zu seinem Hauptkeyword innerhalb von einem Jahr auf der ersten Suchergebnisseite bei Google.
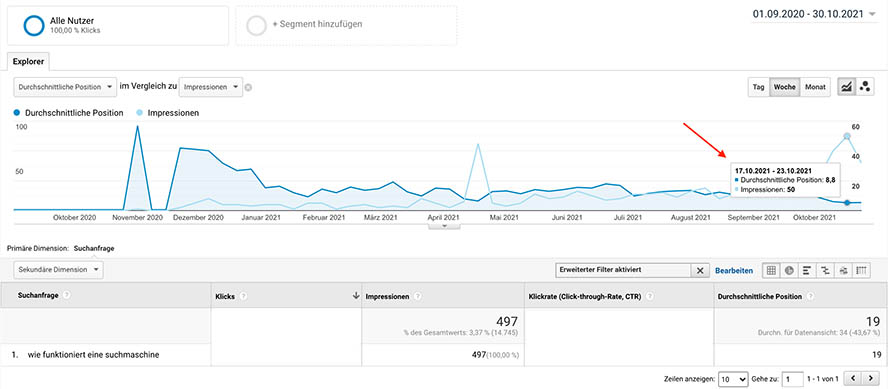
Entwicklung der durchschnittlichen Position und der Anzahl der Impressionen des beschriebenen Blogartikels für das Hauptkeyword „Wie funktioniert eine Suchmaschine?“ im vergangenen Jahr.
Natürlich kann dies verschiedene Gründe haben, es scheint aber für die Qualität des Inhalts zu sprechen. Es könnte zum Beispiel sein, dass die Nutzersignale (durchschn. Sitzungsdauer, Absprungrate) aufgrund der Länge und Einzigartigkeit des Inhalts besser ausfallen als bei anderen Wettbewerbern. Somit kann der Erkenntnisgewinn des Artikels hier zumindest indirekt eine Rolle gespielt haben.
Wie kannst Du die Einzigartigkeit Deiner Inhalte verbessern?
1. Fachbücher, PDFs, PowerPoint- und Word-Dateien suchen
Um einzigartige Inhalte zu erstellen, solltest Du nach Quellen suchen, die für das Thema relevant sind, aber in den aktuellen Suchergebnissen nicht besprochen werden. Hierfür bieten sich Informationen aus PDFs, PowerPoints oder Microsoft Word Dateien an.
Diese lassen sich über die folgenden Suchoperatoren gezielt finden:
- SUCHWORT filetype:pdf
- SUCHWORT filetype:ppt
- SUCHWORT filetype:doc
Fachbücher werden oftmals als PDF konvertiert und hochgeladen. Dies zeigt sich auch beim vorherigen Beispiel zur Funktionsweise einer Suchmaschine. Mithilfe des Suchoperators lassen sich zahlreiche Fachbücher finden, die auf die technischen Hintergründe von Suchmaschinen eingehen und sich somit ideal als Quellen für unseren Artikel eignen.

Mithilfe des Suchoperators können gezielt Fachbücher zum Thema gefunden werden.
2. Auf Internationale Quellen zurückgreifen
Gerade im Online Marketing stammen viele hervorragende Strategien, Techniken und Informationen aus englischsprachigen Publikationen. In einem Webmaster-Hangout im Januar 2020 hat John Müller erklärt, dass Übersetzungen von Google nicht als doppelte Inhalte, sondern als Unique Content angesehen werden.
Durch die Kombination der beiden bisher vorgestellten Techniken (siehe Screenshot) finden sich interessante Quellen zur Funktionsweise einer Suchmaschine.

Der Erkenntnisgewinn des Artikels kann durch Informationen aus englischsprachigen Fachbüchern gesteigert werden.
So führt der obige Suchoperator auf ein PDF-Dokument der Universität Rom, in dem Danny Sullivan – aktueller Google-Berater für Search sowie Co-Gründer des Magazins „SearchEngineLand“ – die technischen Abläufe einer Suchmaschine beschreibt. Dies ist eine ideale Quelle für einen deutschsprachigen Artikel zu diesem Thema.
3. Tools einsetzen, um relevante Unterthemen zu bestimmen
In manchen Fällen können Tools dabei helfen, relevante Unterthemen zu einem bestimmten Oberthema zu recherchieren. Hierfür bieten sich zum Beispiel semantische Analysen aus bekannten SEO-Tools oder spezielle WDF*IDF-Analysen an.

4. Nimm eine andere Perspektive ein
Du musst nicht immer ein neues, relevantes Unterthema finden. In Branchen mit hohem Wettbewerb, wie zum Beispiel dem Online Marketing, werden selbst Nischenthemen stark bespielt. Hier ist es oft schwierig, den Erkenntnisgewinn der Inhalte weiter zu steigern.
In diesem Fall kann es Sinn machen, das Thema aus einer neuen Perspektive zu beleuchten und so einzigartige Inhalte mit hohem Erkenntnisgewinn zu schaffen.
Exkurs: Was ist Unique Content für Google?
Um den Erkenntnisgewinn von Inhalten steigern zu können, ist es wichtig zu verstehen, wie Google einzigartige Inhalte definiert. Der einleitende Twitter-Post von John Müller hat hierzu schon interessante Anhaltspunkte gegeben.
So wissen wir, dass sich Unique Content nicht durch die Verwendung von Synonymen oder kleinen textlichen Anpassungen erzielen lässt. Vielmehr geht es darum, dass wir Inhalte produzieren, die gänzlich oder zumindest zu einem großen Teil einzigartig sind. Inhalte, die sich sehr ähneln, werden von Google nicht indexiert. Dies wird durch eine Meldung auf der Suchergebnisseite angezeigt.

Google schließt sehr ähnliche Treffer von der Suchergebnisseite aus.
Laut Sebastian Erlhofer gilt hierbei die Faustregel, dass der Content mindestens zu 70% einzigartig sein soll. (Erlhofer, S. (2019). Suchmaschinen-Optimierung: Das umfassende Handbuch)
Wie genau Google doppelte Inhalte erkennt, ist nicht bekannt.

Eine weit verbreitete Möglichkeit ist der „Shingle-Algorithmus“. Hierbei wird der gesamte Text in kleinere Abschnitte, die sogenannten „Shingles“ unterteilt. Der Algorithmus vergleicht also kleine, sich überlappende Wortpakete aus verschiedenen Texten miteinander. In der Praxis haben sich hierbei Dreiwortabschnitte (Level-3-Shingles) etabliert.
Das folgende Beispiel beleuchtet die grundlegende Funktionsweise des Verfahrens:
Website A: „Kopierte Texte sind nicht einzigartig“.
Shingle 1: kopierte, texte, sind
Shingle 2: texte, sind, nicht
Shingle 3: sind, nicht, einzigartig
Shingle 4: nicht, einzigartig, kopierte
Shingle 5: einzigartig, kopierte, texte
Auf einer anderen Webseite findet sich folgender, sehr ähnlicher Satz:
Website B: „Einzigartige Texte sind nicht kopiert“.
Shingle 1: einzigartige, texte, sind
Shingle 2: texte, sind, nicht
Shingle 3: sind, nicht, kopiert
Shingle 4: nicht, kopiert, einzigartige
Shingle 5: kopiert, einzigartige, texte
Anschließend wird die Schnittmenge sowie die Vereinigungsmenge zwischen beiden Texten errechnet:
Schnittmenge
Anzahl der Shingles, die in beiden Texten vorkommen (in unserem Fall: 3).
Vereiningungsmenge
Anzahl der Shingles, die entweder zu Text A oder zu Text B gehören (in unserem Fall: 4).
Teilst Du anschließend die Schnittmenge durch die Vereinigungsmenge, kannst Du die Einzigartigkeit der Inhalte berechnen:
Schnittmenge ÷ Vereiningungsmenge = 3/4 = 0,75
Unsere zwei Beispielsätze gleichen sich zu 75%.
Unterschied zwischen internen und externen doppelten Inhalten
Grundsätzlich wird unterschieden, ob sich die Inhalte innerhalb einer Domain gleichen (interner Duplicate Content) oder – wie im obigen Beispiel – die Inhalte zweier unabhängiger Webseiten. Um internen Duplicate Content zu verhindern, solltest Du alle Seiten von der Indexierung ausschließen, bei denen sich Dopplungen nicht vermeiden lassen.
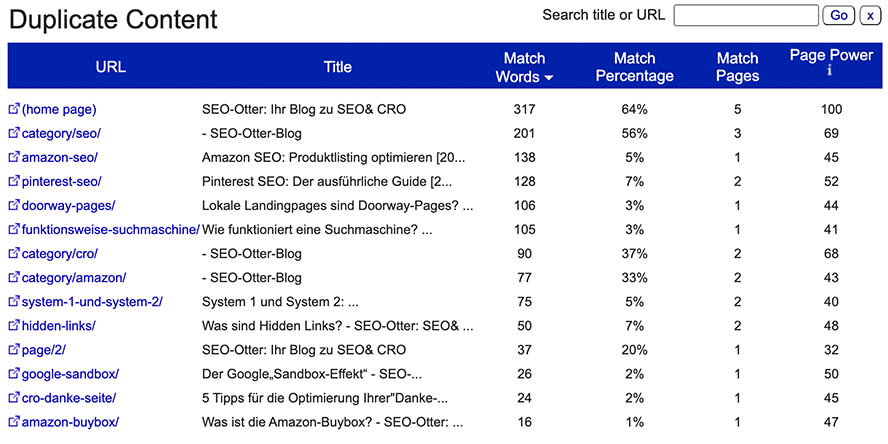
Analyse des Duplicate-Contents innerhalb einer Domain.
Duplicate Content bietet dem Nutzer keinen Mehrwert. Im Gegenteil, im Zusammenhang mit dem Panda-Update ist ein hohes Aufkommen doppelter Inhalte ein negatives Qualitätssignal der Webseite und kann so zu Rankingverlusten oder gar dem Ausschluss aus dem Index führen.
Blick in die Zukunft: Contenterstellung mit AI und SEO-Tools
Automatisierte Contenterstellung mithilfe von künstlicher Intelligenz ist aktuell ein Trendthema in der SEO-Branche. Tools, wie zum Beispiel „Jarvis.ai“ oder „Articoolo“, versprechen hochwertige Inhalte schnell und einfach über AI-Technologie zu erstellen. Doch was bedeutet das für die Einzigartigkeit und den Erkenntnisgewinn des Contents?
Selbstverständlich kann die künstliche Intelligenz Inhalte nicht „selber schreiben“. Vielmehr muss das Tool mit einer bestehenden Datengrundlage gefüttert werden. Basierend auf den gestellten Keyword-Vorgaben handelt es sich hierbei in der Regel um bestehende Suchergebnisse oder Inhalte von Social Media. Die Contenterstellung mithilfe von künstlicher Intelligenz spart zwar Zeit und Ressourcen, trägt aber nicht zu einer hohen Qualität der Inhalte bei.
Stattdessen wird der Effekt verstärkt, dass sich Suchergebnisse stark ähneln und der Erkenntnisgewinn für die Nutzer auf der Strecke bleibt. Bei sehr schlechten Tools droht sogar die Gefahr von Rankingverlusten durch doppelte Inhalte.
Aber auch die bekannten SEO-Tools tragen dazu bei, dass sich Inhalte zu einem bestimmten Thema immer stärker ähneln. Die Empfehlungen der Tools zu den zu verwendenden Keywords, Begriffen und Inhalten basieren auf einer begrenzten Datengrundlage, nämlich den bestehenden Suchergebnissen.

Orientierst Du dich nun zu stark und zu statisch an diesen „Hilfestellungen“ der Tools, leidet die Einzigartigkeit und der Erkenntnisgewinn Deines Artikels darunter.
Daher ist es wichtig, dass Du als Content Marketer den Input der Tools als Hilfestellung erkennst und sie nicht als strikte Vorgaben interpretierst, an die Du Dich sklavisch halten musst, um gute Rankingpositionen bei Google zu erzielen.
Wenn durch das vorgestellte Patent verschiedene einzigartige Inhalte mit unterschiedlichen Sichtweisen ranken, wird die Diversität der Ergebnisse zumindest kurzfristig verstärkt. Langfristig wird sich die Ähnlichkeit der Artikel aber wieder angleichen. Hier wird es spannend sein, zu sehen, ob und wie dynamisch Google den Erkenntnisgewinn von Inhalten beim Ranking in Zukunft berücksichtigt.
Abschließende Gedanken zum Information Gain Score
Die Analyse von Google-Patenten kann dabei helfen, die Algorithmen der Suchmaschine besser zu verstehen und daraus Rückschlüsse für das organische Ranking zu ziehen.
Um Abstand zu nehmen von Umformulierungen und Copycat Content, solltest Du daher immer den Erkenntnisgewinn der eigenen Inhalte im Blick haben. Auch wenn zurzeit noch unklar ist, ob und inwieweit das beschriebene Patent von Google tatsächlich verwendet wird, zeigen die aktuellen Posts von John Müller, dass es sich lohnt, einzigartige Inhalte zu erstellen – für Mensch und Maschine. Automatisierte Contenterstellung mithilfe von künstlicher Intelligenz scheint hierfür aktuell noch nicht die richtige Lösung zu sein.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





