
Was ist Information Retrieval?
Unter Information Retrieval versteht man eine Informationsrückgewinnung oder Informationsbeschaffung. Sie ist ein Bestandteil in der Informatik und der Computerlinguistik. Der Begriff Informationsrückgewinnung ist allerdings genauso wenig aussagekräftig wie der englische Begriff.
Vereinfacht gesagt umfasst Information Retrieval die Aufbereitung von Informationen, die man aus einer großen Datenmenge zurückbekommt. Beim Einsatz dieses Modells werden die Daten allerdings nicht nur sortiert, sondern auch gewichtet zurückgegeben.

Wofür wird Information Retrieval genutzt?
Beim letzten Satz wird Dir ganz sicher ein Stichwort in den Kopf gekommen sein, als ich von Sortierung und Gewichtung von Daten gesprochen habe: richtig, Google. Denn Suchmaschinen nutzen Information Retrieval für das Crawling und den Ranking-Prozess. Informationen werden beschafft, sortiert, gewichtet und in einer Reihenfolge zurückgegeben.
Verschiedene Information Retrieval Modelle
Wenn Du Dich als SEO mit Information Retrieval beschäftigst, laufen Dir früher oder später verschiedene Modelle über den Weg. Zu den wichtigsten gehören dabei:
- Boolesches Modell/Boolesches Retrieval
- einfache Form des Information Retrieval
- es gibt kein Ranking der Informationen, lediglich ihre Indexierung
- Linktopologische Modelle
- es werden Verlinkungen zwischen den Dokumenten ausgewertet
- ein klassisches Beispiel aus der SEO ist der PageRank
- Modelle der Textstatistik
- Terme innerhalb eines Textes werden geprüft und gewichtet
- hierzu zählt die WDF*IDF Berechnung
- Algebraische Modelle
- word2vec als Vektorraummodell
- mathematische Vektorräume werden genutzt, um Ähnlichkeiten und Beziehungen zwischen verschiedenen Themen und Wörtern zu untersuchen
Diese verschiedenen Retrieval Modelle haben unterschiedliche Aufgaben, schließen sich aber nicht gegenseitig aus. Häufig werden sie kombiniert angewandt, um Informationen zurückzugewinnen und diese Datenmengen systematisch zu sortieren.
Google als Retrieval System
Nicht nur diese Modelle zählen zum Information Retrieval System, auch Google selbst stellt ein Retrieval System dar. Dabei kann man den Suchvorgang und die Indexierung in verschiedene Stadien unterteilen.
Im ersten Stadium müssen die Informationen erst einmal in die Datenbank eingespeist werden. Im Falle von Google passiert das durch das Crawlen von Webseiten. Die Inhalte und Meta-Daten werden gespeichert und durch das stetige Crawling auf einem relativ aktuellen Stand gehalten. So ist auch gewährleistet, dass nicht nur alte Webseiten, sondern auch neue hinzugefügt werden. Schließlich gibt es Milliarden Webseiten im Internet und täglich kommen neue hinzu.
Das zweite Stadium ist dann die Ausgabe der gesuchten Informationen. Dies entspricht der klassischen Suchanfrage eines:einer User:in. Die Suchmaschine beschafft also die gewünschten Informationen anhand der Datenbank.
Aber was genau ist daran jetzt Information Retrieval?
Ein Beispiel:
In Deiner Bibliothek werden ständig Bücher abgegeben. Manche davon werden zurückgegeben, andere kommen neu in den Bestand. Bei den alten Büchern schaust Du genau hin, ob sich etwas am Zustand des Buches verändert hat oder ob beispielsweise Seiten herausgerissen wurden. Die neuen Bücher sind noch nicht im System hinterlegt und müssen erst einmal erfasst und in der Kartei angelegt werden. Egal, ob neu oder alt: die Bücher wandern, nachdem Du sie einmal gesehen hast, auf einen Bücherwagen. Hier herrscht Chaos und Du hast gerade auch keine Zeit, die Bücher nach Kategorien oder Bestseller Status zu sortieren.
Am Nachmittag bekommst Du Besuch. Gesucht wird ein Krimi, der im Norden spielt. Du weißt, wo so etwas im Regal steht und begleitest Deine:n Besucher:in dorthin. Angekommen ziehst Du fünf verschiedene Krimi-Romane mit dem gewünschten Setting aus dem Regal. Dabei fällt Dir ein, dass auch auf dem Bücherwagen irgendwo ein neuer Krimi liegt, der ebenfalls zum gesuchten Thema passt. Du holst alle Bücher zusammen und stellst sie Deinem:Deiner Besucher:in vor. Und zwar so, wie Du die Romane einordnen würdest. Du beginnst mit Deiner besten Empfehlung und endest mit einem Krimi-Roman, der die Wünsche des:der Leser:in erfüllt, aber eben nicht so gut wie der Erste.
Wie funktioniert Information Retrieval?
Genau wie im Beispiel arbeitet auch der Suchindex bei Google. Suchmaschinen erfassen zwar alle neuen Daten und Informationen anhand der Webseiten im Netz, allerdings ohne jegliche Ordnung oder Gewichtung. Die Gewichtung wird erst bei der Suchanfrage abgefragt.
Dabei wird die Relevanz der jeweiligen Webseiten zum gesuchten Begriff eingeordnet. Es entstehen die Rankings und schließlich auch die SERPs, die demder User:in zur Suchanfrage ausgespielt werden. Suchmaschinen beachten beim Information Retrieval auch die Art der Suchanfrage.
Sucht jemand nach Inhalten oder vielleicht eher nach Videos, Bildern oder Rezepten? Außerdem ist die Besonderheit bei Suchmaschinen als Information Retrieval System, dass keine konkrete Anfrage an eine Einzeldatei gestellt wird, sondern durch Machine Learning und AI sowie den Algorithmus alles rund um das Thema gesammelt und ausgespielt wird. Dabei bezieht die Suchmaschine auch Entitäten und Vektoren ein.
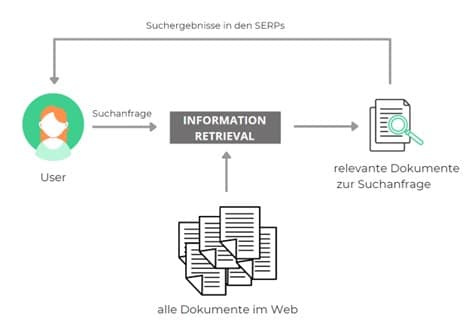
Grafik zur Veranschaulichung eines Information Retrieval Systems anhand einer Suchmaschine
Information Retrieval am Beispiel des Vektorraummodells word2vec
Suchmaschinen können Text verstehen. Allerdings vorrangig durch mathematische Berechnungen. Diese Berechnungen werden durch word2vec gelöst. Wie der Name sagt, konvertiert das Vektorraummodell Wörter in Vektoren. Durch die Vektoren können die Nähe und Beziehung von Begriffen und Themen zueinander erkannt werden.
Word2vec spielt also auch im Information Retrieval eine Rolle, da bei einer Abfrage auch die Ähnlichkeit zwischen den Themen betrachtet wird. Die Suchanfrage, die ein:e User:in stellt, wird einem Vektorraum zugeteilt, in dem sich die verschiedenen Dokumente im Web zum Thema positionieren. Je spitzer jetzt der Winkel zur Suchanfrage ist, desto genauer trifft dieses Ergebnis die Suchintention und das Thema Deiner Suchanfrage.
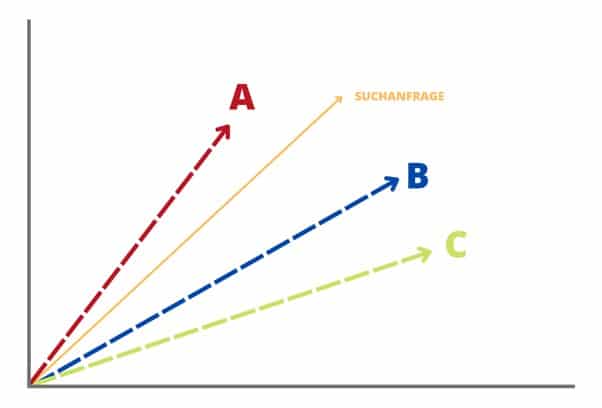
Das Dokument A liegt am nächsten an der Suchanfrage, also dem Wort dran, und hat somit die höchste Ähnlichkeit im Vektorraum.
Dies ist also das beste Suchergebnis, wenn es um die reinen Informationen geht – alle anderen SEO-Faktoren einmal außen vor gelassen. Diese Berechnung einer thematischen Relevanz und Beziehung unter den Wörtern kann nur durch ein Vektorraummodell wie word2vec realisiert werden.
Erfüllung des Search Intents und eigene Themenrelevanz erhöhen
Google wird immer besser darin, zu verstehen, welche Themen zusammenhängen und was der:die Nutzer:in sehen will. Auch durch verschiedene Updates im Algorithmus wurde der Fokus auf Content als Rankingfaktor weiter gestärkt. So zum Beispiel durch BERT, MUM oder Hummingbird.
- Hummingbird ist ein Algorithmus von Google und hat die Aufgabe, die semantische Suche voranzutreiben und Suchanfragen zu interpretieren. Durch Hummingbird wurden auch die großen Updates wie Penguin und Panda realisiert.
- BERT ist die Weiterentwicklung von Hummingbird und nutzt Natural Language Processing (NLP) zur Interpretation von Suchanfragen und deren Kontext.
- MUM beschäftigt sich mit der multimedialen Darstellung von Suchergebnissen und geht auf den Search Intent ein. Sucht ein:e User:in ein Rezept, werden Rezeptvorschläge und Kochvideos gemeinsam mit den normalen Testergebnissen ausgespielt.
Im August 2022 wurde außerdem das Helpful Content Update seitens Google, erst einmal nur für den englischsprachigen Raum, ausgerollt. Alle diese großen Veränderungen im Google Algorithmus stärken die Vermutung, dass Themenrelevanz, Search Intent und Informationsaufbereitung auf der eigenen Landingpage für das eigene Ranking enorm wichtig sind.
Aber wie finde ich passende Themen oder weiterführende Content Ideen, um die Ähnlichkeit zu einem bestimmten Keyword und damit die Relevanz zu erhöhen? Oftmals wird dazu neben einer klassischen Keyword-Recherche und Nutzungsfragen-Analyse auch das WDF*IDF-Modell herangezogen.
Was ist WDF*IDF?
Mit einer WDF*IDF Analyse kannst Du Suchterme identifizieren, die Du in Deinem Inhalt unterbringen solltest, um die Relevanz für Suchmaschinen zu steigern.
WDF*IDF, oft auch als TF*IDF bekannt, heißt ausgeschrieben “Within Document Frequency * Inverse (Document) Frequency” und beschreibt das Vorkommen bestimmter Wörter im eigenen Dokument verglichen mit allen Dokumenten im Web. Bei Information Retrieval geht es immer um eine Gewichtung. So auch bei der WDF*IDF.
WDF ist die “Within Document Frequency” und misst, wie oft ein Term in Deinem eigenen Text vorkommt. Der IDF Wert, also die “Inverse Document Frequency”, setzt die Anzahl aller bekannten Dokumente ins Verhältnis zur Zahl der Texte, die Deinen Term enthalten.
Kombiniert man beide Formeln, indem man sie multipliziert, erhält man eine Gewichtung für den Term anhand des eigenen Textes im Vergleich zu allen Dokumenten im Web, die Dein Keyword enthalten. Diese Gewichtung beschreibt nichts anderes als die Relevanz für das Fokus-Keyword, also das Hauptthema des Textes.
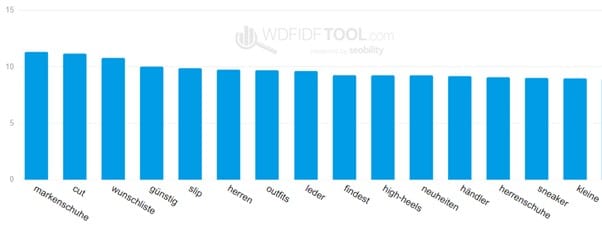
Screenshot SEObility WDF*IDF Tool zum Term “schuhe”
WDF*IDF vs. word2vec
Weiterhin zeigt die WDF*IDF-Analyse passende Keywords, beispielsweise rund um das Thema Schuhe an. Zum Beispiel Schuharten, wie Stiefel oder Sneaker, oder bekannte Marken, die erwähnt werden sollten.
Diese Keywords ergeben sich aus der Analyse aller möglichen Dokumente mit demselben Keyword im Text. Füllwörter oder Begriffe, die eine Doppelbedeutung beinhalten, können durch WDF*IDF nicht gefiltert werden. Dazu kommen eventuell Fremdmarken oder Konkurrenten, die zwar eine hohe Relevanz haben, in der Praxis auf Deiner eigenen Seite aber nichts zu suchen haben.
Anders als beim word2vec-Modell werden hier lediglich Anzahlen und Gewichtungen genutzt, ohne eine thematische Nähe oder Beziehung zwischen den Termen hinzuzuziehen. Bei der WDF*IDF handelt es sich also um eine rein mathematische Berechnung, die man nie zu 100 % auf User:innen orientierte Texte anwenden sollte.
Relevanz von Information Retrieval in der SEO
Durch Information Retrieval-Systeme und Modelle können User:innen das finden, was sie wollen, ohne dass sie ihre Suchanfrage exakt so eingeben müssen, wie sie auf einer Seite steht. Tools oder Modelle wie word2vec oder WDF*IDF können Dir also dabei helfen, Deine eigenen Informationen zu optimieren und im Ranking zu verbessern.
Die Suchintentionen und auch die Nähe zu verwandten Themen oder die holistische Abdeckung des Contents, stellen einen der wichtigsten Punkte in der Suchmaschinenoptimierung dar. Dennoch solltest Du natürlich andere SEO-Faktoren nicht außer Acht lassen, da der Ranking-Algorithmus weiterhin unbekannte Faktoren beinhaltet und sich durch Machine Learning und AI stetig verändern wird.
Fazit
Du kannst eine Waschmaschine nicht reparieren, wenn Du nicht weißt, wie die einzelnen Komponenten zusammengesetzt sind oder wie eine Waschmaschine überhaupt arbeitet. Genauso ist es auch in der Suchmaschinenoptimierung. Um Maßnahmen zu definieren und Optimierungsansätze zu erkennen, musst Du verstehen, wie eine Suchmaschine arbeitet.
Es ist also essenziell zu wissen, wie die Informationen auf meiner Website überhaupt von Google ausgelesen und verarbeitet werden. Die aktuelle Entwicklung hinsichtlich der verschiedenen genutzten Algorithmen von Google, lassen darauf schließen, dass die Relevanz Deines Contents ein essenzieller Rankingfaktor ist.
Wenn Du lernst, wie Du nützliche Inhalte zu den Suchanfragen Deiner Nutzer schreibst, lernst Du automatisch, wie Du für SEO schreiben musst. Denn nur die stumpfe Keyword-Einbindung und Wiedergabe von allgemeinen Informationen, ohne auf die semantische Suche, Entitäten und den Search Intent zu achten, bringt Dich langfristig nicht auf einen grünen SEO-Zweig.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





