
Große Datenmengen fordern Dich heraus? Mit Hilfe von Regulären Ausdrücken kannst Du große Datenmengen schnell bündeln, sodass Du datenbasiert Aussagen treffen kannst. In der Google Search Console kann Regex verwendet werden, um gezielt bestimmte URL-Muster zu filtern, Suchanfragen zu kategorisieren oder spezifische Trends in den Nutzerdaten zu erkennen.

Was ist ein Regulärer Ausdruck?
Ein Regulärer Ausdruck beschreibt einfach gesagt eine bestimmte Zeichenreihenfolge. Diese Zeichenreihenfolge wird auch Pattern genannt. Die Regex-Funktion überprüft eine Datenmenge auf dieses Pattern und siebt alle nicht-übereinstimmenden Zeichenfolge aus.
Als Begründer der regulären Ausdrücke gilt übrigens der amerikanische Mathematiker und Logiker Stephen Cole Kleene. Seine Werke sind heute Grundlage für die theoretische Informatik.
Reguläre Ausdrücke werden oft mit Regex oder im Englischen für Regular Expressions mit RegExp abgekürzt. Reguläre Ausdrücke können als Filterfunktion oder in Texteditoren in der Funktion des Suchen und Ersetzens zum Einsatz kommen.
Beide Fälle finden Anwendung in der SEO. Denn gerade bei größeren Datenmengen und Webseiten hilft Dir Regex dabei, die einzelnen URLs für die Analyse zu strukturieren. Auch Datenmengen aus der Google Search Console lassen sich mit Regex schnell und unkompliziert clustern und zum Beispiel in Lookerstudio darstellen. In der technischen Optimierung dienen reguläre Ausdrücke zudem für die Weiterleitung von URLs mit demselben Muster in der .htaccess-Datei.
Die wichtigsten Regex-Operatoren
Damit die Suche nach Pattern greifen kann, muss die Beziehung der einzelnen Zeichen definiert werden. Dafür gibt es sogenannte Operatoren, die die Zeichen in spezifische Pattern gruppieren und sie in eine Beziehung zueinander stellen. So kann nach Teilen oder des gesamten Patterns gesucht werden (und- bzw. oder -Operator) und auch die Häufigkeit, wie oft die Zeichen vorkommen, dürfen spezifiziert werden. Ebenso können die vorangehenden oder die nachfolgenden Zeichen benannt werden.
Reguläre Ausdrücke bilden sich durch das Alphabet bzw. numerische Zeichen in Kombination mit den sogenannten Metazeichen [ ] ( ) { } | ? + – * ^ $ \ . . Ein Backslash kann diese Metazeichen negativieren also ungültig machen.
Die Bedeutung der Metazeichen
| [] | In eckigen Klammern steht die entsprechende Zeichenauswahl. |
| – | Der Bindestrich kann unterschiedlich interpretiert werden. Steht er innerhalb der Zeichenkette, wird er als ‘bis’ verstanden. [a-c] bedeutet, es wird nach a, b, und c gesucht. Steht der Bindestrich am Anfang oder Ende der Zeichenreihenfolge [a,b,c,-] wird er als Bindestrich interpretiert. |
| [^] | Steht ^ am Anfang einer Zeichenkette, negativiert es die folgenden Zeichen. ^a bedeutet, es darf kein a vorkommen. steht es irgendwo in der Zeichenkette, wird es als
^ interpretiert. |
| | | Steht für die Alternative.[a | b] es muss entweder ein a oder ein b vorkommen. |
| $ | Je nach Kontext endet die Zeilen- oder die Zeichenkette an dieser Stelle. |
| . | Für den Punkt darf ein beliebiges Zeichen in der Reihenfolge stehen. |
| * | Das vorangehende Zeichen darf beliebig oft vorkommen. |
| \s | Steht als kleingeschriebenes S für ein Leerzeichen. |
Einige Beispiele für typische RegExp
| Regex | Ergebnis |
| [omt] | Entweder o,m oder t wird gesucht |
| [0-9] | Beliebige Zahl wird gesucht |
| [A-Za-z0-9] | Beliebige zahl oder Ziffer wird gesucht |
Ist Regex eine Programmiersprache?
Auch wenn Regex auf den ersten Blick wie eine eigene Programmiersprache wirken mag, streng genommen ist es das nicht. Reguläre Ausdrücke finden aber in den verschiedenen Programmiersprachen Anwendung, wie zum Beispiel HTML, JavaScript, Perl, Python, Ruby oder XML. Da in diesen Sprachen einige der Metazeichen bereits belegt sind, können sich die Regular Expressions von Sprache zu Sprache leicht unterscheiden. Dadurch ergibt sich die Unterscheidung in Shell Namensmuster, Basic Regular Expressions und Extended Regular Expressions.
Mit Regex mehr aus den Daten der Google Search Console herausholen
Regex kann dir dabei helfen, die Daten aus der Google Search Console besser zu strukturieren. Zum Beispiel dann, wenn deine URL-Struktur die einfache Filterung nicht zulässt, da der Subfolder ausgeblendet oder nicht kohärent ist. Eine der häufigsten Anwendungsbeispiele ist die Clusterung von Suchbegriffen nach Intention oder Brand-Bezug.
Non-Brand vs Brand Traffic ermitteln
Mit Hilfe von Regex kannst Du deinen Non-Brand / Brand Traffic Share herausfinden. Dafür kannst Du direkt in der Google Search Console den Filter Suchanfragen nutzen. Am Beispiel vom OMT könnte das folgendermaßen aussehen:
.*omt.* | .*online marketing treff.* | .*omt.de.*
Dieser Regex-Befehlt filtert nach den Kombinationen mit “omt”, “online marketing treff” oder der website “omt.de”. In der GSC hast Du die Möglichkeit entweder nach Übereinstimmung oder nach Nicht-Übereinstimmung zu filtern. Für den Brand-Traffic wählst Du folgendes aus:
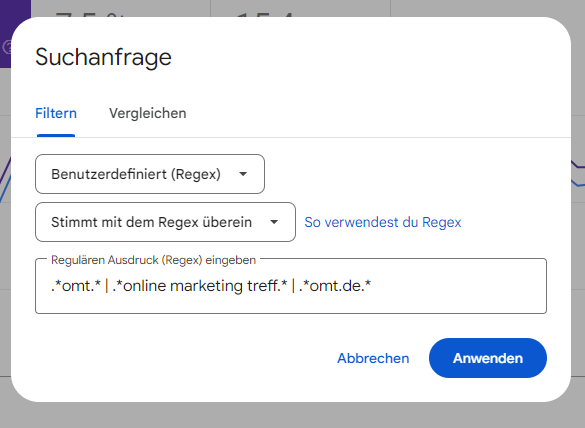
In der Google Search Console kannst Du mithilfe von Regex-Befehlen deinen Brand-Traffic ermitteln. Quelle: Google Search Console.
Möchtest Du den Brand-Traffic herausfiltern, so wählst Du ‘Stimmt nicht mit dem Regex überein’. Die Google Search Console zeigt Dir entsprechend die KPI (Impressions, Clicks, CTR und Position) für einen Teil der Suchanfragen. Dadurch kannst Du den Share von Brand vs Non-Brand Traffic ermitteln.
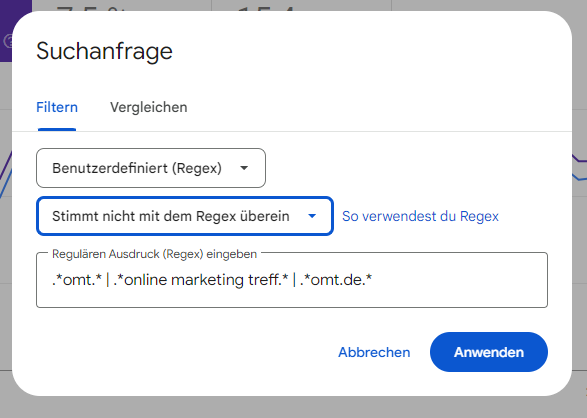
Für den Non-Brand-Traffic stellst du in der Google Search Console ‘stimmt nicht überein’ ein. Quelle: Google Search Console.
Schneller und übersichtlicher geht es, wenn Du die Google Search Console in Lookerstudio angebunden hast. Dann kannst Du einen Query-Filter mit Hilfe von Regex erstellen. Hier wählst Du dann im Drop-Down Filter Non-Brand aus, werden wieder nur Suchanfragen ohne “omt”, “online marketing treff”, oder “omt.de” angezeigt.
Allerdings werden Begriffe wie “online marketing” richtigerweise zu Non-Brand gezählt, da wir im Filter angeben, dass zwar vor und nach ‘online marketing treff’ andere Zeichen stehen dürfen, die drei Worte aber in der Reihenfolge nicht unterbrochen werden dürfen. Allerdings werden Rechtschreibfehler wie “otm” oder “online marketi treff” dann ebenfalls zu Non-Brand gewertet.
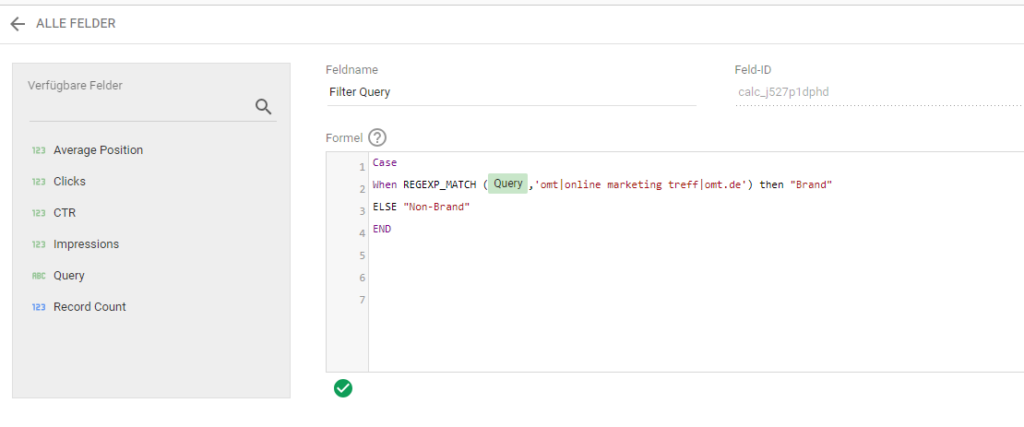
In Lookerstudio kannst Du mithilfe von Regex Filter erstellen, dir die Trennung zwischen Non-Brand und Brand erleichtern. Quelle: Lookerstudio.
Um jetzt den Non-Brand / Brand-Traffic Share auf einen Blick zu ermitteln, kannst Du zwei Kreisdiagramme erstellen. Als Dimension wählst Du das neu erstellte Feld ‘Filter Query’ aus und definierst in unserem Beispiel als Messwert Impressions bzw. Clicks aus.
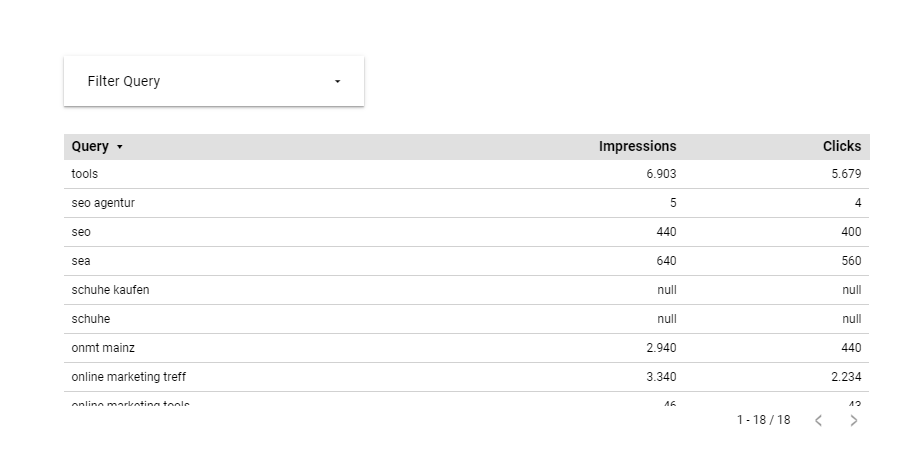

Die erstellen Regex-Filter kannst du entweder als Dimension oder als Filter im Report nutzen. Quelle: Lookerstudio, fiktive Daten.
Case
When REGEXP_MATCH (Query,’omt|online marketing treff|omt.de’) then “Brand” When REGEXP_MATCH (Query,’.*omt.*|.*online marketing treff.*|.*omt.de.*’) then “Compound”
ELSE “Non-Brand” END
Kombinationen mit “omt” (z.B. “omt podcast”) würde dann als Compound Keyword gewertet. Die exakte Eingabe von “omt” oder “online marketing treff” hingegen würde weiterhin der Brand-Gruppe zugeordnet.
Wenn Du einen Online Shop betreibst, macht es auch Sinn, transaktionale von informativen oder Brand-Suchanfragen zu differenzieren. Dafür kannst Du im Filter typische Begriffe wie “kaufen”, “bestellen”, “günstig”, “angebot” ,“preis” zu transaktional zu ordnen.
Fragen in den Search Queries identifizieren
Regex kann Dir auch helfen, häufig gesuchte Fragen in den Queries der Google Search Console zu identifizieren. Achtung, Dir werden dabei aber lediglich die Fragen angezeigt, für die Deine Domain bereits in den Suchergebnissen erscheint. Es dient also nicht dazu, Fragen zu recherchieren, die für Deine relevanten Keywords bei Google ausgespielt werden. Durch die Identifizierung der W-Fragen in der Google Search Console kannst Du allerdings die bereits gewonnenen Rankings prüfen und im nächsten Schritt den Content anpassen, um die Platzierungen zu verbessern.
(\s|^)w(er|em|en|essen|ie|ann|o|elche|as|obei|omit|oran|ohin|obei|eshalb|arum|ieso|orauf|oru m|ovor|odurch|oher|eswegen|oraus)\s
Das Zeichen “\s” steht dabei für ein Leerzeichen. “^” steht für beginnt mit. Übersetzt heißt der Reguläre Ausdruck folglich, dass das Query entweder mit dem Fragewort beginnt oder ein Leerzeichen vor dem Fragewort steht. Dadurch wird sowohl “was ist der omt” als auch “omt was ist das” gefunden.
“.*” funktioniert in diesem Fall nicht, da sonst auch Queries ausgegeben werden, die keines der angegebenen W-Frageworte enthalten. Zum Beispiel wäre dann auch das Query “clubtreffen wiesbaden” denkbar. Dasselbe passiert, wenn das “\s” am Ende vergessen wird, denn dann können wiederum variable Zeichen nach den in Klammer angegebenen Zeichenfolgen stehen. “\s” definiert also, dass die in der Klammer angegebenen Buchstabenreihenfolge zwischen zwei Leerzeichen stehen müssen.
Subfolder analysieren
Neben den Search Queries kannst Du in der Google Search Console auch nach einzelnen Seiten bzw. Subfoldern filtern. Wenn Dich die Klicks für einen kompletten Subfolder interessieren, kannst Du das ganz einfach durch die Auswahl “URLs mit” filtern. Hier im Beispiel werden nur alle URLs unterhalb des Webinare-Subfolder gefiltert.
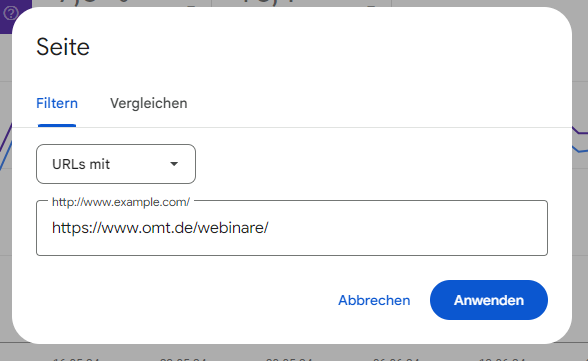
Die Filterfunktion für URLs in der Google Search Console kann dann ungenau sein, wenn nicht alle gewünschten URLs im selben Subfolder liegen. Quelle: Google Search Console.
Dadurch beziehst Du allerdings Seiten wie “https://www.omt.de/google-ads-webinare/” nicht in Deine Analyse mit ein. Mit dem Regex .*/.*webinare.*/.* schließt Du sowohl alle URLs des Subfolders /webinare/ ein, als auch alle URLs, die im Subfolder “webinare” stehen haben.
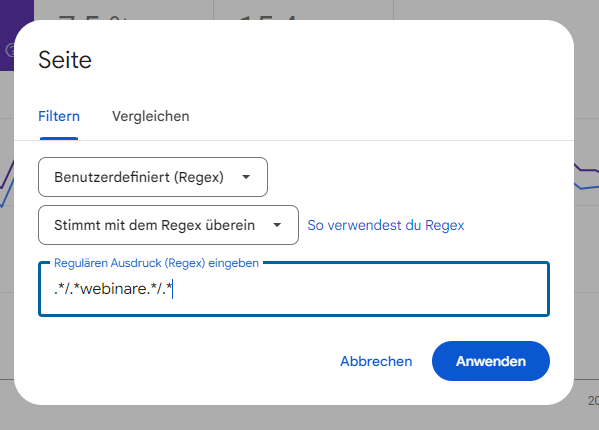
Mit Regex kannst du die Zuordnung von URLs zu einer bestimmten Gruppe genauer vornehmen. Quelle: Google Search Console.
Gleiches könntest Du auch für spezifische Themen umsetzen. Der Regex .*/.*seo.*/.* würde dann alle URLs mit in die Betrachtung einbeziehen, die SEO in ihrer URL besitzen.
Case
When REGEXP_MATCH(Address,’.*/online-marketing-tools/.*’) then “Online Marketing Tools”
When REGEXP_MATCH(Address,’.*/.*seminare/.*’) then “Seminare”
When REGEXP_MATCH(Address,’.*/agentur-finden/.*’) then “Agentur finden” When REGEXP_MATCH(Address,’.*/service/.*’) then “Service”
When REGEXP_MATCH(Address,’.*/.*webinare.*/.*’) then “Webinare” When REGEXP_MATCH(Address,’.*/clubtreffen/.*’) then “Clubtreffen” When REGEXP_MATCH(Address,’.*/podcasts.*/.*’) then “Podcasts” Else “Sonstiges”
End
Auch hier ist wieder der Platzhalter “.*” vor Webinare und Seminare eingefügt worden, um die Übersichtsseiten zu den einzelnen Themen in den jeweiligen Subfolder miteinzubeziehen. Willst Du die “echten” Subfolder betrachten, könntest Du in unserem Beispiel auch
When REGEXP_MATCH(Address,’https://www.omt.de/webinare/.*’) then “Webinare”
nutzen. Beachte, wenn Deine Übersichtsseite nicht mit dem Trailing Slash endet, in unserem Fall also https://www.omt.de/webinare, dann musst Du Deinen Filter noch um einen weiteren Regulären Ausdruck ergänzen:
When REGEXP_MATCH(Address,’https://www.omt.de/webinare/.*’) then “Webinare” When REGEXP_MATCH(Address,’https://www.omt.de/webinare$’) then “Webinare”
Das Zeichen “$” gibt an, dass die URL genau auf “webinare” endet. Nur so wird Lookerstudio deine Übersichtsseite auch in Deine Subfolder-Kategorie aufnehmen.
Das neue Feld kannst Du als Filter einsetzen und so die einzelnen URLs eines Subfolders analysieren. Eine weitere Möglichkeit ist, das Feld als Dimension innerhalb einer Tabelle zu verwenden und so die unterschiedlichen Subfolder im Vergleich zueinander zu betrachten.
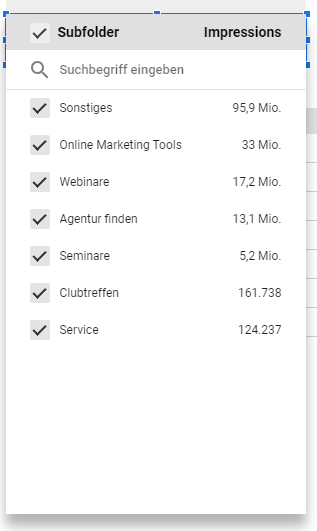
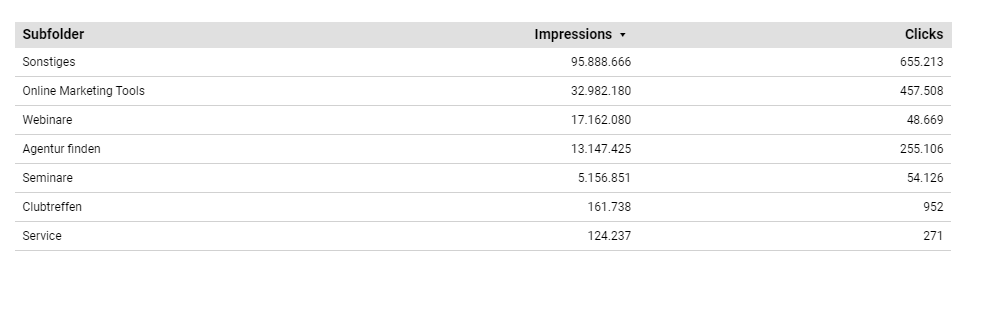
Auch Subfolder lassen sich in Lookerstudio mit Regex als Filter oder Dimension definieren. Quelle: Lookerstudio, fiktive Daten.
Weiterleitungen in .htaccess-Datei
Neben der Analyse und Strukturierung von Daten sind Reguläre Ausdrücke auch wichtige Hilfsmittel, um alltägliche Aufgaben zu beschleunigen. So lassen sich auch Weiterleitungen mit Hilfe von regulären Ausdrücken vereinfachen. Reguläre Ausdrücke können Dir zum Beispiel bei der Umstrukturierung einer Domain einiges an Arbeit erleichtern.
Angenommen, der OMT würde seinen Download-Subfolder in eine neue Struktur überführen. Die Dateinamen sollen die gleichen bleiben, der Zusatz /download/ in der URL soll allerdings wegfallen. So könnte jetzt jede einzelne URL in der htaccess-Datei einzeln mit folgendem Befehl weitergeleitet werden:
Redirect 301 /ebooks/ https://www.omt.de/downloads/ebooks/ Redirect 301 /magazin/ https://www.omt.de/downloads/magazin/
Schneller geht’s mit einem regulären Ausdruck, der alle betroffenen URLs in die neue Struktur überführt:
RedirectMatch 301 ^/downloads/(.*)$ https://www.omt.de/$1
Dieser reguläre Ausdruck sucht nun alle URLs, die mit “downloads” starten und einen beliebigen Zusatz haben und leitet sie auf die neue URL mit demselben Zusatz, aber ohne
/downloads/-Subfolder weiter.
Wenn der Subfolder nicht nur gelöscht, sondern ersetzt werden soll, kann auch das durch einen regulären Ausdruck gelöst werden. In unserem Beispiel ersetzen wir /downloads/ durch /neuer-subfolder/:
RedirectMatch 301 ^/downloads/(.*)$ https://www.omt.de/neuer-subfolder/$1
Ein anderer denkbarer Fall könnte die Weiterleitung von sehr ähnlichen Inhalten auf eine Ziel-URL sein. Gleichen sich die betroffenen URLs so kann auch hier nach einem entsprechenden Muster gesucht werden und eine Weiterleitungsregel genügt:
RedirectMatch 301 ^/templates/(.*)-templates/$ https://www.omt.de/templates/
Hier im Beispiel des OMT werden die verschiedenen Templates für Youtube, LinkedIn, E-Mail und Instagram auf die URL https://www.omt.de/templates/ weitergeleitet.
Ein weiteres typisches Beispiel ist die Reduzierung der URLs um die Dateiendung. Sollen die neuen URLs nicht länger mit “.html” ausgegeben werden, so definiert der folgende Befehl in der .htaccess-Datei dies für alle URLs:
RedirectMatch 301 ^/(.*).html$ https://www.omt.de/$1
Reguläre Ausdrücke beim Crawlen großer Websites
Reguläre Ausdrücke kommen auch vorbereitend für Weiterleitungen zum Einsatz und sind unglaublich nützlich für die Analyse großer Websites. So kannst Du Deinen Crawl mit Screamingfrog deutlich beschleunigen, wenn Du Regex in der Include-/ Exclude-Funktion des Crawlers verwendest:

Auch beim Crawlen von großen Websites kann Regex hilfreich sein, um den Crawl zu präzisieren und somit deutlich zu beschleunigen. Quelle: Screamingfrog.
Besonders hilfreich ist diese Funktion bei einem größeren Shop. Wenn Du in Deiner Analyse nur Kategorieseiten berücksichtigen möchtest, spart es viel Zeit, die Produktseiten zu exkludieren.
Reguläre Ausdrücke testen
Es ist noch kein Meister vom Himmel gefallen, das gilt auch (oder vor allem) für Reguläre Ausdrücke. Verschiedene Programme helfen Dir dabei, Deine erstellten Regex zu testen und ggf. anzupassen.
- Auf https://regex101.com/ kannst Du Deine Regulären Ausdrücke eingeben und modifizieren. Zudem gibt Dir das Tool die dahinter liegende Erklärung zum Befehl aus.
- Mit https://regexr.com/ kannst Du Deinen Regex-Befehl auf einen von Dir eingefügten Text testen. Nützlich zum Beispiel, wenn Du Deine Suchbegriffe aus der Google Search Console clustern möchtest.
- Neben dem Debuggen bietet Dir https://www.regextester.com/ zusätzlich noch eine Bibliothek typischer Anwendungsfälle sowie ein Cheat Sheet für alle Meta Zeichen und Kombinationen aus diesen und numerischen bzw. alphabetischen Ausdrücken.

Praktisch das Cheat-Sheet für Regex Meta-Zeichen von Regextester. Quelle: regextester.com
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





