
Die Suchfunktion ist eines der zentralen Elemente vieler Websites. Insbesondere im E-Commerce spielt sie eine wichtige Rolle, denn laut Forrester findet bei 43 % aller Nutzer:innen von Onlineshops die erste Interaktion über die Suchleiste statt (Quelle: forrester.com).
Trotzdem scheitern 42 % aller Websites daran, zufriedenstellende Suchergebnisse zu liefern, weil die Suche beispielsweise relevante Synonyme zu den eigenen Kategorien nicht erkennt (Quelle: baymard.com).
Das liegt daran, dass viele Seiten auch heute noch auf die klassische Volltextsuche auf Basis von Keywords setzen. Diese hat auch viele Vorteile. Vor allem, weil die Suche über Keywords Teil unseres erlernten Nutzerverhaltens ist und die Tools dafür, wie Elasticsearch oder OpenSearch, weitverbreitet und oft bereits in CMS und Shopsystemen integriert sind.
Das Problem ist, dass die Volltextsuche, vor allem wenn sie nicht sehr gut eingerichtet wurde, nur dann gute Ergebnisse liefert, wenn die Nutzer:innen bereits wissen, wonach sie suchen. Bei der Suche nach Konzepten oder Kontext versagen sie jedoch in der Regel.
Eine Lösung dafür können sogenannte vektorbasierte Suchmaschinen sein, also Suchmaschinen, die auf Vektordatenbanken basieren. Sie können eine Alternative zu herkömmlichen Keyword-basierten Anwendungen sein, eignen sich aber noch besser als Ergänzung. Die vektorbasierte Suche hat den Vorteil, dass der oder die Nutzer:in auch kontextbezogen suchen oder Fragen stellen kann.
Was sind vektorbasierte Suchmaschinen?
Vektorsuchen basieren auf so genannten Vektordatenbanken. Ein Vektor stellt die Entfernung zu einer Eigenschaft dar (Quelle: data-science-blog.com). Ein besonders einfaches Beispiel sind Koordinaten, also eine Suche nach zwei Dimensionen eines Vektors (Längen- und Breitengrad).
Sucht ein:e User:in nach Berlin, so liegt Potsdam näher als Stuttgart. Dieses Prinzip kann auf jede beliebige Eigenschaft angewendet werden. Zum Beispiel ist OMT näher an der Eigenschaft Marketing als Chaos Communication Congress und Pimcore liegt näher an der Eigenschaft PIM als Bloomreach.
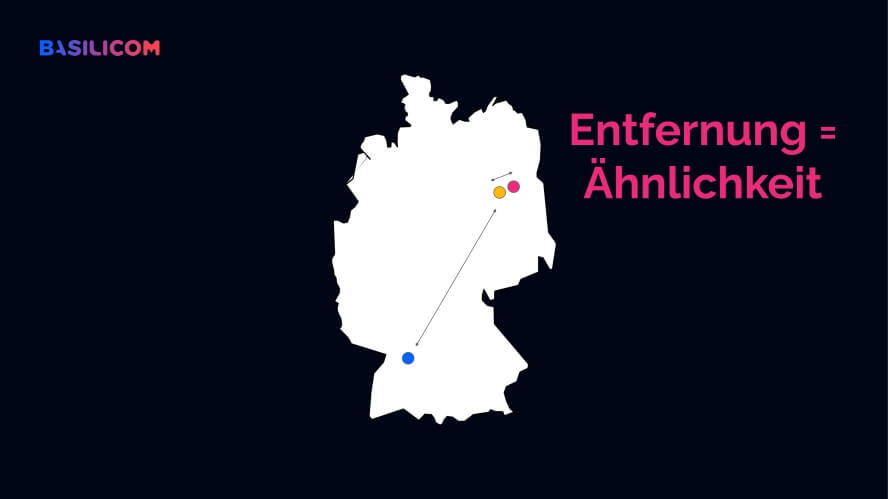
Koordinaten sind eine einfache Version von Vektoren. Die Entfernung zum gesuchten Ziel entspricht der Nähe zu einer Eigenschaft. (Quelle: Basilicom / Christoph Lühr)
Jede Eigenschaft in der Vektordatenbank hat ihren eigenen Vektor. Der Wert dieses Vektors gibt den Abstand zur Eigenschaft an.
Für die Eigenschaft Marketing hätte OMT dann z.B. den Wert 0,99 und Chaos Communication Congress den Wert 0,3. Sucht ein:e User:in also nach Marketing Konferenz, so basieren die Ergebnisse also nicht darauf, wie oft das Wort Marketing und verwandte Begriffe im Suchergebnis vorkommen, sondern darauf, welche Ergebnisse den Eigenschaften Marketing und Konferenz am nächsten liegen.
Dies funktioniert auch mit den Eigenschaften eines Produktes in einem Onlineshop oder den Eigenschaften einer Person in einem CDP. Diese können in Vektoren gespeichert und durchsuchbar gemacht werden, um bessere Suchergebnisse zu erzielen.
Was haben Vektordatenbanken mit künstlicher Intelligenz zu tun?
Vektordatenbanken sind kein völlig neues Konzept. Unternehmen wie Pinecone (2019) oder Qdrant (2021) bieten bereits seit einigen Jahren entsprechende Lösungen an. Durch die weite Verbreitung von Large Language Models (LLMs), insbesondere ChatGPT, gewinnen Vektordatenbanken auch für Unternehmen an Bedeutung, die selbst keine KI-Modelle entwickeln.
Generative KIs wie LLMs verwenden Vektoren, um Sprache zu verstehen. Gibt man ChatGPT einen Text zur Verarbeitung, erzeugt die KI automatisch Vektoren. Bisher wurden Vektordatenbanken daher vor allem für den Aufbau und das Training von KI- und Machine-Learning-Modellen benötigt.
Die von einer KI erzeugten Vektoren können aber auch über eine API abgerufen, gespeichert und durchsuchbar gemacht werden. Bei den meisten KI-Modellen spricht man dann von der “Embeddings API”, da die Embeddings die numerische, abstrakte Repräsentation der Inhalts-Vektoren sind.
Um eine Suchmaschine zu bauen, kann man also alle Inhalte per API an ein LLM, z.B. ChatGPT, senden und die daraus generierten Vektoren in einer Vektordatenbank speichern. Diese Datenbank kann dann wiederum mit Hilfe des LLM durchsucht werden.
Diese Suche basiert dann auf dem verwendeten Sprachmodell, hat also grundsätzlich die gleichen Fähigkeiten und das gleiche semantische Textverständnis wie z.B. ChatGPT, StableM, ALEPH ALPHA, Claude AI oder Mistral AI.
Um daraus eine funktionsfähige Suche zu machen, müssen die Vektoren in der Datenbank hinterlegt werden. Für eine gute User Experience bei der Suche sind Vektoren mit einigen hundert oder mehr Dimensionen empfehlenswert (Quelle: infoworld.com).
Im Falle von ChatGPT werden beispielsweise Vektoren mit 1.536 Dimensionen generiert (Quelle: Openai.com). So wie LLMs diese Vektoren verwenden, um das beste oder wahrscheinlichste nächste Wort zu berechnen (Quelle: cliffguren.com), um Anfragen zu beantworten (Textgenerierung), können sie die Vektoren verwenden, um den besten bekannten Inhalt zu einer Anfrage zu berechnen.

Beispielhafte Visualisierung eines Vektors (Embedding) mit 2000 Dimensionen, wie sie von einem LLM wie ChatGPT erstellt werden könnte. (Quelle: Basilicom / Christoph Lühr)
Was sind die Vorteile einer vektorbasierten Suche?
Vektorbasierte Suchmaschinen sind letztlich eine KI-Suche, sie nutzen also die Vorteile der künstlichen Intelligenz, um Inhalte auffindbar zu machen. Dadurch versteht die Suche die Eingaben besser und kann auch multimedial genutzt werden. Das bedeutet, in Zukunft können Vektorsuchen auch Suchanfragen auf Basis von Bildern, Ton oder sogar Videos verarbeiten.
Integration und Skalierung von Vektorsuchen
Eine KI-basierte Suche ist, einmal implementiert, schnell und einfach skalierbar. Vektordatenbanken auf Basis von LLMs ermöglichen eine effiziente Verarbeitung auch großer Datensätze, da kein eigenes Training erforderlich ist – die Suche baut auf dem Wissen eines bestehenden Sprachmodells.
Es müssen im Gegensatz zur Volltextsuche neue Kategorien nicht manuell hinzugefügt werden. Das Sprachmodell übernimmt diese Aufgabe automatisch für alle Inhalte, die es über die API erhält.
Verbessertes Textverständnis
LLMs verfügen über das gesamte Wissen, mit dem sie trainiert wurden. ChatGPT verfügt beispielsweise über 175 Milliarden Parameter (Quelle: sciencefocus.com). Moderne Sprachmodelle sind daher sehr gut darin, Sprache zu verstehen.
Für die Suche hat dies mehrere Vorteile:
- Tippfehler und unterschiedliche Schreibweisen werden in der Regel automatisch erkannt und müssen nicht hinterlegt werden.
- Es kann auch nach Kontext gesucht werden, ohne das eigentliche Produkt oder Stichwort zu kennen.
- Die Suche funktioniert automatisch in jeder Sprache, die das verwendete LLM versteht.
- Vektordatenbanken können für alle Daten und Medien (multimodal) verwendet werden, nicht nur für Text.
Tippfehler und Synonyme
Bei der klassischen Volltextsuche müssen unterschiedliche Schreibweisen, mögliche Tippfehler oder Synonyme in der Regel manuell eingegeben werden. Da vektorbasierte Suchmaschinen auf KI-Sprachmodellen basieren, verfügen sie über das gleiche Wissen wie das zugrunde liegende LLM.
Die KI erkennt Anomalien also automatisch. Sie erkennt, ob es sich um einen Rechtschreibfehler handelt oder beispielsweise, dass SEO und Suchmaschinenoptimierung dasselbe sind.
Kontextsuche
Ein weiterer Vorteil der vektorbasierten Suche ist, dass sie nicht nur mit Schlüsselwörtern gut funktioniert, sondern auch den Kontext erkennt. Die Volltextsuche funktioniert sehr gut, wenn der oder die Benutzer:in bereits weiß, wonach er oder sie sucht.
Schwieriger wird es, wenn nach einer bestimmten Funktionalität, einem Konzept oder einem Inhalt gesucht wird. Wer zum Beispiel auf imdb.com nach “detektiv london” sucht, findet viele Filme über Detektive in London, aber nicht die wahrscheinlichste Antwort: Sherlock Holmes.
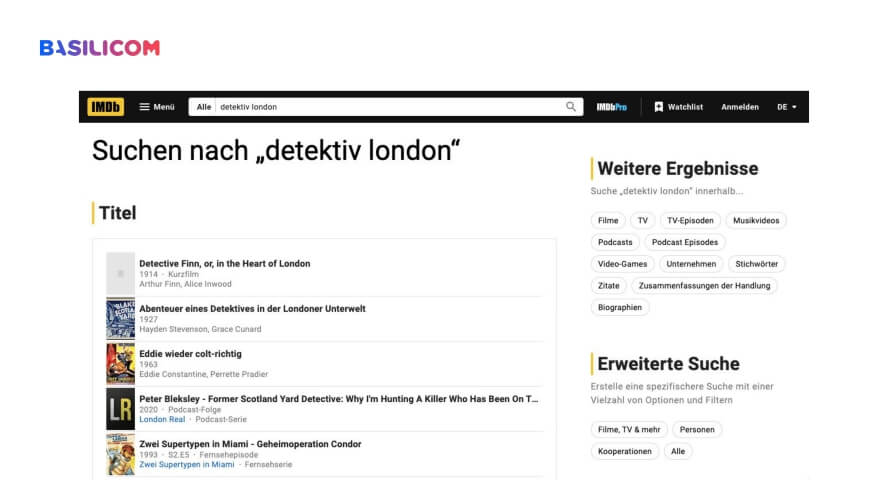
Suche nach “detektiv london” bei der imdb.com. (Quelle: IMDB.com / Christoph Lühr)
Dieses textuelle Verständnis von LLMs hat jedoch zusätzliche Vorteile. Zum Beispiel können sich Unternehmen mehr auf die gesamte Nutzererfahrung konzentrieren, anstatt einzelne Elemente optimieren zu müssen.
Zum Beispiel müssen Texte wie Produktbeschreibungen nicht mehr bestimmte Keywords berücksichtigen. Ähnlich wie bei Google, wo die Keyworddichte für die SEO keine Rolle mehr spielt, müssen Marketer:innen also nicht zugunsten der Auffindbarkeit in der eigenen Suche auf Mehrwert für den oder die Nutzer:in verzichten.
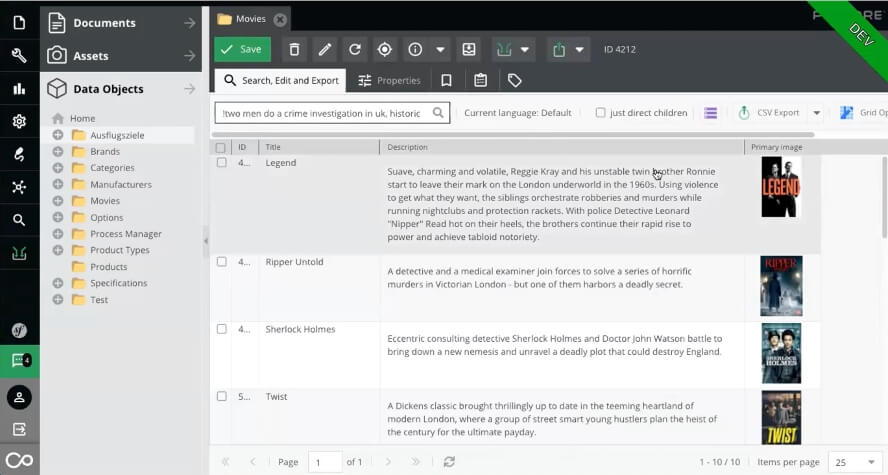
Suche nach “two men do a crime investigation in uk, historic” mit einer Vektorsuche in Pimcore. (Quelle: Basilicom / Christoph Lühr)
Das hat auch den Vorteil, dass längere Inhalte wie Blogartikel, Ratgeber, Anleitungen oder FAQs besser durchsuchbar werden. Denn der oder die Nutzer:in ist nicht mehr gezwungen, eine möglichst exakte Wortkombination zu finden, sondern kann konkrete Problemstellungen abfragen oder nach Zusammenhängen suchen.
Mehrsprachigkeit
Da die meisten LLMs mit Inhalten in verschiedenen Sprachen ausgebildet wurden, bedeutet dies auch, dass sie Inhalte in all diesen Sprachen verstehen. ChatGPT kann beispielsweise 85 verschiedene Sprachen verarbeiten (Quelle: botpress.com).
Der Vorteil ist nicht nur, dass eine auf ChatGPT basierende KI-Suche Vektoren für Inhalte in diesen Sprachen generieren kann, sondern auch, dass die Suche relevante Ergebnisse für alle Sprachen liefern kann, selbst wenn die Inhalte nicht in der Sprache verfügbar sind.
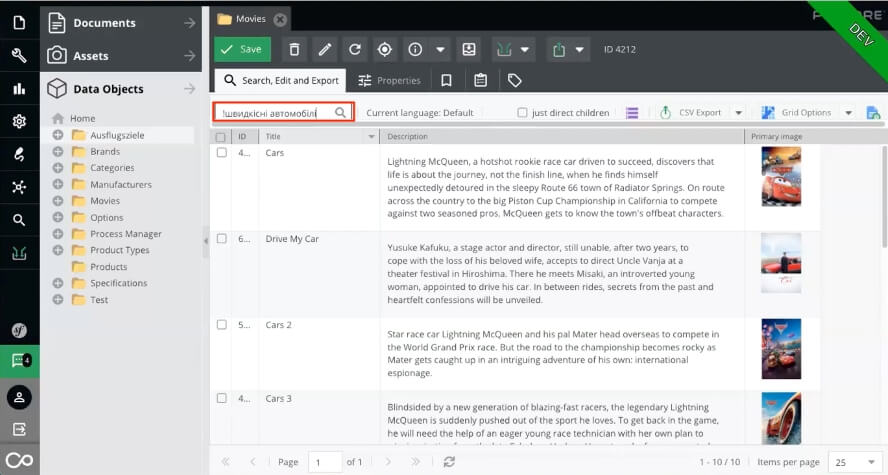
Inhalte wie Filmbeschreibungen können mit Vektoren aus einem LLM in jeder Sprache (hier Ukrainisch) durchsucht werden, selbst wenn der Text nicht in der Sprache verfügbar ist. Screenshot aus Pimcore. (Quelle: Basilicom / Christoph Lühr)
So könnten beispielsweise Behörden Formulare oder Informationen auch in Fremdsprachen besser auffindbar machen.
Multimodalität
Im Gegensatz zur Volltextsuche funktioniert die vektorbasierte Suche auch multimodal, also medienübergreifend. Theoretisch funktioniert das mit allen, auch multimedialen Inhalten wie Videos.
In der Praxis funktioniert es vor allem mit Texten und Bildern sehr gut, aber multimodale KI-Modelle, die z.B. für die Analyse von Videos benötigt werden, sind noch nicht weit genug entwickelt, um vergleichbare Ergebnisse zu liefern.
Damit könnten beispielsweise Stockfotodatenbanken oder Unternehmen mit eigenen internen Asset-Portalen ihre Suche verbessern, da die Suche nicht mehr von der korrekten Benennung der Dateien und Tags abhängt, sondern vom tatsächlichen Inhalt des Bildes.
Nachteile vektorbasierter Suchmaschinen
Im Vergleich zu herkömmlichen Anwendungen sind KI-Suchfunktionen in der Regel aufwendiger zu implementieren. Da Standardintegrationen sowohl bei Anbietern von Suchlösungen als auch bei Tools wie CMS-, PIM- oder Shopsystemen bisher die Ausnahme sind, müssen Unternehmen die APIs derzeit selbst anbinden.
Zudem ist ein Grundverständnis von Vektordatenbanken oder zumindest die Zeit und Erfahrung, sich dieses anzueignen, erforderlich.
Daher ist die Einführung einer KI-Suche zunächst mit zusätzlichen Kosten und zusätzlicher Arbeit für Entwickler:innen verbunden. Volltextsuchen sind derzeit außerdem noch schneller und die Kosten pro Abfrage bzw. Speicherplatz sind geringer.
Ein weiterer Nachteil ist, dass KI-Modelle Kontext benötigen, um Vektoren zu erstellen. Dadurch können sie zwar längere und komplexere Anfragen besser verarbeiten und somit bessere Antworten auf Long-Tail-Suchen liefern, allerdings setzt dies voraus, dass genügend Inhalte vorhanden sind.
Steht beispielsweise für ein Produkt keine Produktbeschreibung, sondern nur einzelne Informationen wie Name, Größe oder Gewicht zur Verfügung, wird eine Vektorsuche auch bei komplexen Anfragen keine besseren Ergebnisse liefern als eine Volltextsuche.
Vektorbasierte Suchmaschinen lohnen sich daher vor allem für Unternehmen oder Websites, die über eine große Anzahl von Daten in Form von Produkten oder Inhalten mit ausreichend Content verfügen.
Für Unternehmen mit einem kleinen Produktkatalog, vielen Produkten mit sehr geringen Margen oder einem schnell wechselnden Sortiment, bei denen die Erstellung von Inhalten für jedes einzelne Produkt sehr aufwendig ist, wird eine KI-Suche kaum Vorteile bringen.
Für Wikipedia würde eine KI-Suche daher wahrscheinlich bessere Suchergebnisse liefern und die Nutzererfahrung verbessern. Im Gegensatz dazu müsste Vinted (Marktplatz für Secondhand-Fashion, ehem. Kleiderkreisel) für jeden Artikel, der von Nutzer:innen online gestellt wird, erst eine Beschreibung erzeugen und durch ein LLM verarbeiten lassen, selbst wenn der Artikel nur wenige Tage online ist.
Dafür müsste man von den Nutzer:innen entweder eine Vielzahl an Produktinformationen abfragen oder sie eine Beschreibung hochladen lassen. Vinted müsste also erhebliche Kompromisse bei der Usability eingehen, um die Suche zu verbessern.
Voraussetzungen für eine effiziente Vektorsuche
Grundsätzlich muss ein Unternehmen natürlich erst einmal in der Lage sein, Vektoren über eine KI zu generieren, in einer Vektordatenbank abzulegen und dann in eine Suche einzubinden. Das heißt, es müssen die technischen Ressourcen intern oder extern vorhanden sein und es muss ein Techstack, z.B. das CMS oder PIM, vorhanden sein, der solche Verknüpfungen ermöglicht.
Ist diese Voraussetzung erfüllt, braucht man vor allem Content, aus dem die KI Embeddings generieren kann. Es gibt keine feste Regel oder Mindestmenge an Content, die benötigt wird. Da Vektoren jedoch auf Cluster basieren, die die Nähe von Inhalten, z.B. Wörtern, zueinander darstellen, kann eine KI aus mehr Content auch mehr Vektoren und bessere Cluster bilden.
Im Gegensatz zu einer minimalen Länge gibt es jedoch eine maximale Länge von Tokens, die ein KI-Modell verarbeiten kann. Die Anzahl der Tokens wird Kontextlänge genannt. Bei Azure OpenAI und GPT 4 sind dies ca. 8.000 Tokens (Open AI bietet auch eine GPT-4 Variante mit 32.000 Tokens an) (Quelle: microsoft.com, openai.com). Ein Token entspricht ca. 4 Zeichen, so dass Texte bis zu 2.000 Wörtern in der Regel problemlos verarbeitet werden können.
Es ist auch möglich, längere Inhalte aufzuteilen, was als Chunking bezeichnet wird. Das Problem dabei ist, dass die KI dann Vektoren für die einzelnen “Chunks” erstellt. Chunking kann dazu führen, dass Zusammenhänge zwischen den Chunks (local context) oder Zusammenhänge, die sich erst aus dem gesamten Inhalt ergeben (global context), in den Vektoren nicht abgebildet werden (Quelle: openai.com). Auch hier gilt also die Faustregel “so lang wie nötig, so kurz wie möglich”.
Für die eigene Suche ist es übrigens kein Problem, wenn Texte mit KI geschrieben wurden. Sie sollten natürlich trotzdem einen Mehrwert bieten. Gerade die Erstellung von Produktbeschreibungen lässt sich fast vollständig automatisieren, wenn man sein PIM- oder Shopsystem mit KI-Tools wie ChatGPT oder Texttools wie Retresco verbindet.
In diesem Zusammenhang macht es auch Sinn, das Thema User Generated Content wieder stärker in den Fokus zu rücken. Denn auch (Produkt-)Bewertungen liefern zusätzlichen Kontext und können so die Suche verbessern. Darüber hinaus bietet KI viele weitere Möglichkeiten, wie z.B. automatische Sentimentanalysen, um Feedback besser zu nutzen.
Fazit
Eine vektorbasierte Suche kann die Benutzererfahrung erheblich verbessern. Sie ist der Volltextsuche insbesondere bei Longtail-Suchen überlegen. Zusätzlich ermöglicht sie den Nutzer:innen auch nach Kontext und nicht nur nach Stichworten zu suchen.
Ein weiterer Vorteil ist, dass sie auch für andere Inhaltsformate wie Bilder, Tonaufnahmen oder auch multimediale Inhalte funktioniert.
Allerdings benötigen sie auch genügend Kontext, um effektiv zu funktionieren. Außerdem ist die Implementierung und der Betrieb bisher teurer als die normale Stichwortsuche. Ist die Vektorsuche aber einmal implementiert, lässt sie sich sehr gut skalieren.
Insbesondere Unternehmen mit sehr großen Produktkatalogen und umfangreichen Inhalten profitieren von vektorbasierten Suchmaschinen. Für Unternehmen mit einem kleinen Produktsortiment oder einem sehr schnell wechselnden Sortiment kann der Aufwand für die Implementierung bzw. Content-Produktion höher sein als der gewonnene Mehrwert.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen





